

Section: New Results
Category-level object and scene recognition
Task-Driven Dictionary Learning
Participants : Julien Mairal, Jean Ponce, Francis Bach [INRIA SIERRA] .
Modeling data with linear combinations of a few elements from a learned dictionary has been the focus of much recent research in machine learning, neuroscience and signal processing. For signals such as natural images that admit such sparse representations, it is now well established that these models are well suited to restoration tasks. In this context, learning the dictionary amounts to solving a large-scale matrix factorization problem, which can be done efficiently with classical optimization tools. The same approach has also been used for learning features from data for other purposes, e.g., image classification, but tuning the dictionary in a supervised way for these tasks has proven to be more difficult. In this paper, we present a general formulation for supervised dictionary learning adapted to a wide variety of tasks, and present an efficient algorithm for solving the corresponding optimization problem. Experiments on handwritten digit classification, digital art identification, nonlinear inverse image problems, and compressed sensing demonstrate that our approach is effective in large-scale settings, and is well suited to supervised and semi-supervised classification, as well as regression tasks for data that admit sparse representations.
This work has resulted in a publication [4] .
Ask the locals: multi-way local pooling for image recognition
Participants : Y-Lan Boureau, Jean Ponce, Nicolas Le Roux [INRIA SIERRA] , Francis Bach [INRIA SIERRA] , Yann LeCun [New York University] .
Invariant representations in object recognition systems are generally obtained by pooling feature vectors over spatially local neighborhoods. But pooling is not local in the feature vector space, so that widely dissimilar features may be pooled together if they are in nearby locations. Recent approaches rely on sophisticated encoding methods and more specialized codebooks (or dictionaries), e.g., learned on subsets of descriptors which are close in feature space, to circumvent this problem. In this work, we argue that a common trait found in much recent work in image recognition or retrieval is that it leverages locality in feature space on top of purely spatial locality. We propose to apply this idea in its simplest form to an object recognition system based on the spatial pyramid framework, to increase the performance of small dictionaries with very little added engineering. Stateof- the-art results on several object recognition benchmarks show the promise of this approach.
This work has resulted in a publication [7] .
A Graph-matching Kernel for Object Categorization
Participants : Olivier Duchenne, Armand Joulin, Jean Ponce.
This paper addresses the problem of category-level im- age classification. The underlying image model is a graph whose nodes correspond to a dense set of regions, and edges reflect the underlying grid structure of the image and act as springs to guarantee the geometric consistency of nearby regions during matching. A fast approximate algorithm for matching the graphs associated with two images is pre- sented. This algorithm is used to construct a kernel appro- priate for SVM-based image classification, and experiments with the Caltech 101, Caltech 256, and Scenes datasets demonstrate performance that matches or exceeds the state of the art for methods using a single type of features.
This work has resulted in an ICCV 2011 publication [9] (oral presentation).
A Tensor-Based Algorithm for High-Order Graph Matching
Participants : Olivier Duchenne, Jean Ponce, Francis Bach [INRIA SIERRA] , Inso Kweon [KAIST, Korea] .
This paper addresses the problem of establishing correspondences between two sets of visual features using higher-order constraints instead of the unary or pairwise ones used in classical methods. Concretely, the corresponding hypergraph matching problem is formulated as the maximization of a multilinear objective function over all permutations of the features. This function is defined by a tensor representing the affinity between feature tuples. It is maximized using a generalization of spectral techniques where a relaxed problem is first solved by a multi-dimensional power method, and the solution is then projected onto the closest assignment matrix. The proposed approach has been implemented, and it is compared to state-of-the-art algorithms on both synthetic and real data.
This work has resulted in an PAMI publication [2] .
Clusterpath: an algorithm for clustering using convex fusion penalties
Participants : Armand Joulin, Toby Hocking [INRIA SIERRA] , Francis Bach [INRIA SIERRA] , Jean-Philippe Vert [Mines ParisTech] .
We present a new clustering algorithm by proposing a convex relaxation of hierarchical clustering, which results in a family of objective functions with a natural geometric interpretation. We give efficient algorithms for calculating the continuous regularization path of solutions, and discuss relative advantages of the parameters. Our method experimentally gives state-ofthe-art results similar to spectral clustering for non-convex clusters, and has the added benefit of learning a tree structure from the data.
This work has resulted in an publication [10] .
An MRF model for binarization of natural scene text
Participants : Karteek Alahari, Anand Mishra [IIT India] , C.V. Jawahar [IIT India] .
Scene text recognition has gained significant attention from the computer vision community in recent years. Recognizing text in the wild is a challenging problem, even more so than the recognition of scanned documents. In this work, we focus on the problem of cropped word recognition. We present a framework that exploits both bottom-up and top-down cues. The bottom-up cues are derived from individual character detections from the image. We build a Conditional Random Field model on these detections to jointly model the strength of the detections and the interactions between them. We impose top-down cues obtained from a lexicon-based prior, i.e. language statistics, on the model. The optimal word represented by the text image is obtained by minimizing the energy function corresponding to the random field model.
We show very significant improvements in accuracies on two challenging public datasets, namely Street View Text (over 15%) and ICDAR 2003 (over 10%).
This work has resulted in an publication [12] .
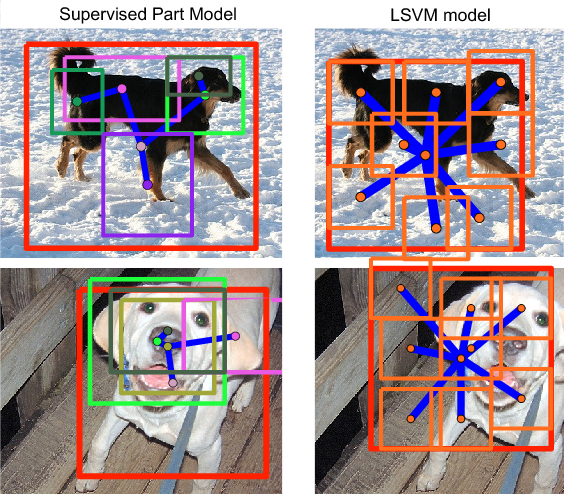
Strongly-supervised deformable part model for object detection
Participants : Hossein Azizpour [KTH Stockholm] , Ivan Laptev, Stefan Carlsson [KTH Stockholm] .
Deformable part models achieve state-of-the-art performance for object detection while relying on the greedy initialization during training. The goal of this paper is to investigate limitations of such initialization and to improve the model for the case when part locations are known at the training time. To this end, we deploy part-level supervision and demonstrate improved detection results when learning models with manually-initialized part locations. We further explore the benefits of the strong supervision and learn model structure by minimizing the variance among adjacent model parts. Our method can simultaneously handle samples with and without part-level annotation making benefit even from a fraction of fully-annotated training samples. Experimental results are reported for the detection of six animal classes in PASCAL VOC 2007 and 2010 datasets. We demonstrate significantly improved performance of our model compared to the state-of-the-art LSVM object detector and poselet detector. Example learnt models are shown in figure 3 .
This work has resulted in a submission to CVPR 2012.
|
Exploiting Photographic Style for Category-Level Image Classification by Generalizing the Spatial Pyramid
Participant : Jan van Gemert [University of Amsterdam] .
This paper investigates the use of photographic style for category-level image classification. Specifi
cally, we exploit the assumption that images within a category share a similar style defi
ned by attributes such as colorfulness, lighting, depth of fi
eld, viewpoint and saliency. For these style attributes we create correspondences across images by a generalized spatial pyramid matching scheme. Where the spatial pyramid groups features spatially, we allow more general feature grouping and in this paper we focus on grouping images on photographic style. We evaluate our approach in an object classification task and investigate style differences between professional and amateur photographs. We show that a generalized pyramid with style-based attributes improves performance on the professional Corel and amateur Pascal VOC 2009 image datasets.
This work has resulted in a publication [20] .
Generalized Fast Approximate Energy Minimization via Graph Cuts: Alpha-Expansion Beta-Shrink Moves
Participants : Karteek Alahari, Mark Schmidt [INRIA SIERRA] .
We present alpha-expansion beta-shrink moves, a simple generalization of the widely-used alpha beta-swap and alpha-expansion algorithms for approximate energy minimization. We show that in a certain sense, these moves dominate both alpha beta-swap and alpha-expansion moves, but unlike previous generalizations the new moves require no additional assumptions and are still solvable in polynomial-time. We show promising experimental results with the new moves, which we believe could be used in any context where alpha-expansions are currently employed.
This work has resulted in a publication [17] .