

Section: Research Program
Experimental Methodologies for the Evaluation of Distributed Systems
Distributed systems are very challenging to study, test, and evaluate. Computer scientists traditionally prefer to study their systems a priori by reasoning theoretically on the constituents and their interactions. But the complexity of large-scale distributed systems makes this methodology near to impossible, explaining that most of the studies are done a posteriori through experiments.
In AlGorille, we strive at designing a comprehensive set of solutions for experimentation on distributed systems by working on several methodologies (formal assessment, simulation, use of experimental facilities, emulation) and by leveraging the convergence opportunities between methodologies (co-development, shared interfaces, validation combining several methodologies).
Simulation and Dynamic Verification
Our team plays a key role in the SimGrid project, a mature simulation toolkit widely used in the distributed computing community. Since more than ten years, we work on the validity, scalability and robustness of our tool.
Our current medium term goal is to extend the tool applicability to Clouds and Exascale systems. In the last years, we therefore worked toward disk and memory models in addition to the previously existing network and CPU models. The tool's scalability and efficiency also constitutes a permanent concern to us. Interfaces constitute another important work axis, with the addition of specific APIs on top of our simulation kernel. They provide the “syntactic sugar” needed to express algorithms of these communities. For example, virtual machines are handled explicitly in the interface provided for Cloud studies. Similarly, we pursue our work on an implementation of the full MPI standard allowing to study real applications using that interface. This work may also be extended in the future to other interfaces such as OpenMP or OpenCL.
We integrated a model checking kernel in SimGrid to enable formal correctness studies in addition to the practical performance studies enabled by simulation. Being able to study these two fundamental aspects of distributed applications within the same tool constitutes a major advantage for our users. In the future, we will enforce this capacity for the study of correctness and performance such that we hope to tackle their usage on real applications.
Experimentation on testbeds and production facilities, emulation
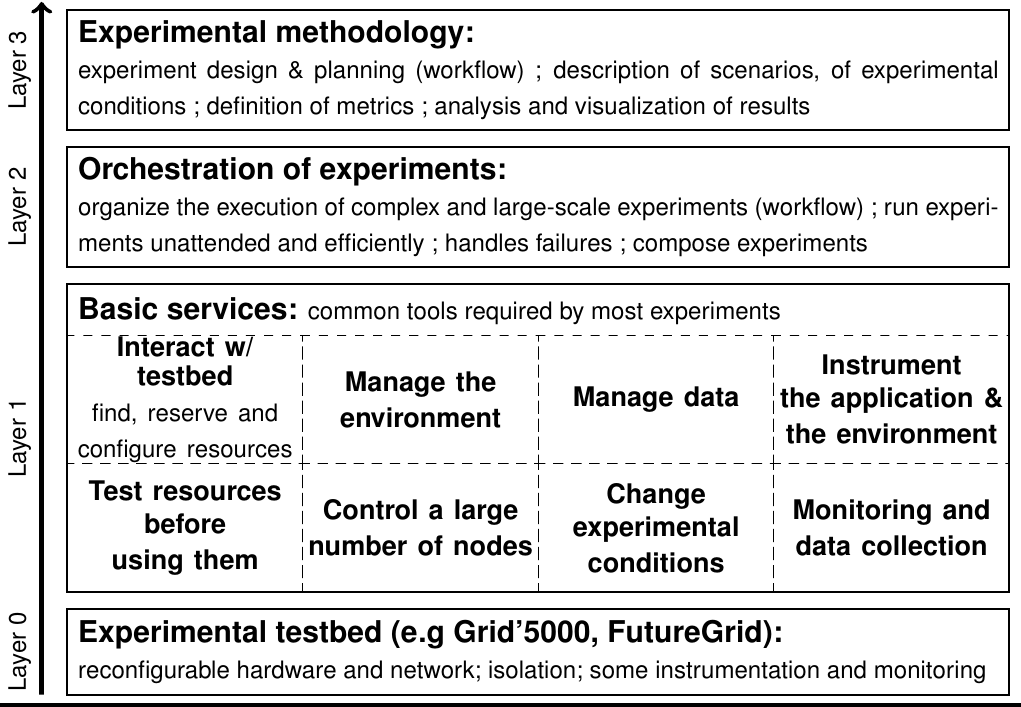
Our work in this research axis is meant to bring major contributions to the industrialization of experimentation on parallel and distributed systems. It is structured through multiple layers that range from the design of a testbed supporting high-quality experimentation, to the study of how stringent experimental methodology could be applied to our field, as depicted in Figure 2 .
During the last years, we have played a key role in the design and development of Grid'5000 by leading the design and technical developments, and by managing several engineers working on the platform. We pursue our involvement in the design of the testbed with a focus on ensuring that the testbed provides all the features needed for high-quality experimentation. We also collaborate with other testbeds sharing similar goals in order to exchange ideas and views. We now work on basic services supporting experimentation such as resources verification, management of experimental environments, control of nodes, management of data, etc. Appropriate collaborations will ensure that existing solutions are adopted to the platform and improved as much as possible.
One key service for experimentation is the ability to alter experimental conditions using emulation. We work on the Distem emulator, focusing on its validation and on adding features (such as the ability to emulate faults, varying availability, churn, load injection, etc) and investigate if altering memory and disk performance is possible. Other goals are to scale the tool up to 20000 virtual nodes while improving the tool usability and documentation.
We work on orchestration of experiments in order to combine all the basic services mentioned previously in an efficient and scalable manner, with the design of a workflow-based experiment control engine named XPFlow.
|
Convergence and co-design of experimental methodologies
We see the experimental methodologies we work on as steps of a common experimental staircase: ideally, one could and should leverage the various methodologies to address different facets of the same problem. To facilitate that, we must co-design common or compatible formalisms, semantics and data formats.
Other experimental sciences such as biology and physics have paved the way in terms of scientific methodology. We should learn from other experimental sciences, adopt good practices and adapt them to Computer Science's specificities.
But Computer Science also has specific features that make it the ideal field to create a truly Open Science: provide infrastructure and tools for publishing and reproducing experiments and results, linked with our own methodologies and tools.
Finally, one important part of our work is to maintain a deep understanding of systems and their environments, in order to properly model them and experiment on them. Similarly, we need to understand the emerging scientific challenges in our field in order to improve adequately our experimental tools.