
Keywords
Computer Science and Digital Science
- A1.3. Distributed Systems
- A1.3.3. Blockchain
- A3.1.4. Uncertain data
- A3.1.7. Open data
- A3.1.8. Big data (production, storage, transfer)
- A3.3. Data and knowledge analysis
- A3.3.1. On-line analytical processing
- A3.3.3. Big data analysis
- A3.5.1. Analysis of large graphs
- A5.1. Human-Computer Interaction
- A5.1.1. Engineering of interactive systems
- A5.1.2. Evaluation of interactive systems
- A5.1.6. Tangible interfaces
- A5.1.8. 3D User Interfaces
- A5.1.9. User and perceptual studies
- A5.2. Data visualization
- A5.6.1. Virtual reality
- A5.6.2. Augmented reality
- A6.3.3. Data processing
- A9.6. Decision support
Other Research Topics and Application Domains
- B1. Life sciences
- B1.1. Biology
- B1.2. Neuroscience and cognitive science
- B9.5.6. Data science
- B9.6. Humanities
- B9.6.1. Psychology
- B9.6.3. Economy, Finance
- B9.6.6. Archeology, History
- B9.6.10. Digital humanities
1 Team members, visitors, external collaborators
Research Scientists
- Jean-Daniel Fekete [Team leader, Inria, Senior Researcher, HDR]
- Pierre Dragicevic [Inria, Researcher]
- Steve Haroz [Inria, Starting Research Position]
- Tobias Isenberg [Inria, Senior Researcher, HDR]
- Petra Isenberg [Inria, Researcher]
- Catherine Plaisant [Inria, International Chair, Advanced Research Position]
Post-Doctoral Fellows
- Luiz Augusto De Macedo Morais [Inria, from Aug 2020]
- Paola Tatiana Llerena Valdivia [Inria, until May 2020]
- Gaelle Richer [Inria]
PhD Students
- Yuheng Feng [Univ Paris-Saclay]
- Sarkis Halladjian [Inria]
- Jiayi Hong [Inria]
- Mohammad Alaul Islam [Inria]
- Alexis Pister [Inria]
- Mickael Sereno [Inria]
- Natkamon Tovanich [Institut de recherche technologique System X]
- Xiyao Wang [Inria]
- Lijie Yao [Inria, from Sep 2020]
Technical Staff
- Christian Poli [Inria, Engineer]
Interns and Apprentices
- Rafael Blanco Guerra [Inria, from Mar 2020 until Aug 2020]
- Stephane Gosset [Inria, from Mar 2020 until Aug 2020]
- Lijie Yao [Inria, from Mar 2020 until Aug 2020]
- Yuanyang Zhong [Inria, from Apr 2020 until Jul 2020]
Administrative Assistant
- Katia Evrat [Inria]
External Collaborators
- Paolo Buono [Université de Bari - Italie]
- Paola Tatiana Llerena Valdivia [Telecom ParisTech, from Jun 2020]
- Evelyne Lutton [INRAE, HDR]
- Catherine Plaisant [Université du Maryland - College Park USA]
- Frédéric Vernier [Univ Paris-Saclay]
2 Overall objectives
2.1 Objectives
Aviz (Analysis and VIsualiZation) is a multidisciplinary project that seeks to improve data exploration methods, techniques, and tools based on Interactive Visualization. Visualization, in general, refers to the graphical representation of data or concepts to aid access, distribution or explanations of data. Card et al. give a general definition for visualization as
“the use of computer-supported, interactive, visual representations of data to amplify cognition.” 76
Taking this definition, visualization is a means of creating visual aids that lead to insight in the underlying data sets. It is not about producing nice pictures but about making data understandable and explorable so that visualizations help viewers gain knowledge about the data. It is about aiding the process of forming a mental model for the acquired data and so helping the viewer to understand underlying concepts, patterns, and connections within the data 133. In partiular, visualization has the goal to improve humans' sensemaking of complex data by taking advantage of the capabilities of their vision system: visual information can be processed in parallel and with a high bandwidth into the human cognitive centers 143. Ware defines five advantages of visualization 143:
- Comprehension: Supports the comprehension of large amounts of data.
- Pattern Perception: Previously unnoticed properties of data may emerge.
- Problem Analysis: Problems within the data may become immediately apparent.
- Adaptability: facilitates understanding of large- and small-scale features of data.
- Interpretation: Hypothesis formulation is facilitated.
Three main areas of visualization have evolved in the computer science community: Scientific Visualization, Information Visualization, and Visual Analytics. Scientific visualization is primarily concerned with displaying real or simulated scientific data. Basic visualization techniques for this area include surface rendering, volume rendering, and animation. Typical examples include processing of satellite photographs, fluid flows, or medical data. Datasets in information visualization typically come from large information spaces or information systems and are both structured or unstructured. Examples include network data, multi-dimensional tables of abstract measurements, or unstructured data such as text. Visual analytics, finally, is concerned with augmenting human-led data exploration with automatic techniques such as machine learning. The Aviz team has expertise in all three areas of visualization.
As shown in
On the system side, we want to expand the scope of visualization that is currently limited to relatively small datasets and relatively simple analytical methods. To achieve scalability in visualization, we will focus on a paradigm shift: progressive data analysis. Long-running computations currently hamper the exploration and visualization process because human's attention is limited by latency constraints. We want to design exploratory systems that provide continuous feedback and allow interactions at any time during computation. The new progressive data analysis paradigm offers these capabilities, but to be usable, it requires the whole analytical pipeline to be re-implemented, and visualization and interaction techniques to be adapted.
2.2 Research Themes
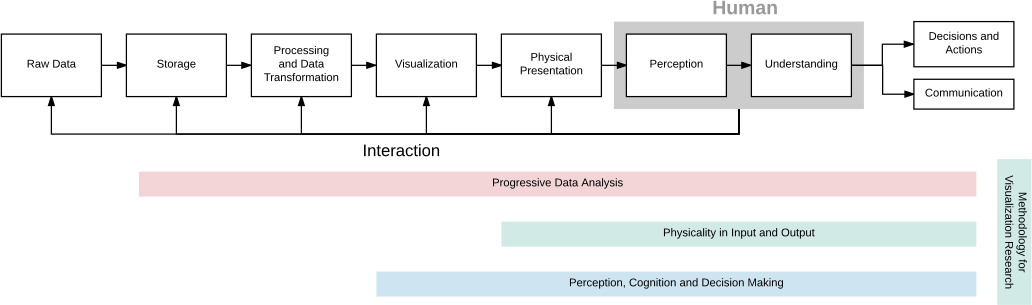
Aviz's research on Visualization and Visual Analytics is organized around four research themes, described in more detail in the next section. Instead of addressing point problems, each research theme will address several stages of the visualization pipeline in a holistic manner, as summarized in
1. Progressive Data Analysis will address visualization scalability problems. Existing data analysis systems (such as Tableau 137, R 138, or Python with its data analysis ecosystem 110) are not scalable for exploratory analysis because their latency is not controllable. This theme will lay out the foundations of progressive data analysis systems, which generate estimates of the results and updates the analyst continuously at a bounded pace. It will focus on all the stages of the data analysis pipeline: data management mechanisms, data analysis modules, as well as visualizations, perception, understanding, and decision making.
2. Physicality in Input and Output will seek to better understand the benefits of physicality for information. Although beyond-desktop environments for visualization are generating more and more interest, theories and empirical data are lacking. This theme will consolidate the nascent areas of data physicalization, situated visualization, and immersive visualization.
3. Perception, Cognition, and Decision Making will study how we perceive and understand visualizations in order to develop generalized guidelines for optimizing effectiveness. It will generalize results obtained with simple charts to more complex visualizations of large datasets, establish theories on the use of abstraction in visualization, and contribute new empirical knowledge on decision making with visualizations.
4. Methodologies for Visualization Research will develop new methods to ground the study of the above scientific questions, and to benefit visualization more generally. This theme will develop evidence-based strategies for communicating quantitative empirical findings, and will promote methodological discussions and open research practices within the field.
3 Research program
3.1 Progressive Data Analysis
Permanent involved: Jean-Daniel Fekete
While data analysis has made tremendous progresses in scalability in the last decade, this progress has only benefited “confirmatory” analysis or model-based computation; progress in data exploration has lagged behind.
Existing data analysis systems do not support data exploration at scale because, for large amounts of data or for expensive computations, their latency is not controllable: computations can take minutes, hours, even days and months. Cognitive psychologists have shown that humans cognitive capabilities degrade when latency increases 126, 132. Miller 126 points out that the feedback of a system should remain below 10 seconds to maintain the user's attention. Therefore, to try to limit the latency, analysts currently resort to complex, inefficient, and unsatisfactory strategies, such as sampling with its issues related to representativity.
To address the scalability problem under controlled latency, instead of performing each computation in one long step that forces the analyst to wait for an unbounded amount of time, a progressive system generates estimates of the results and updates the analyst continuously at a bounded pace. The process continues until the computation is complete, or it stops early if the analyst considers that the quality of the estimates is sufficient to make a decision. During the process, a progressive system allows users to monitor the computation with visualizations and steer it with interactions.
While the topic of progressive data analysis has started to emerge in the late 90's, it has remained marginal practically because it touches three fields of computer science that are traditionally separate: data management, data analysis, and visualization. Research on progressive data analysis remains fragmented; the solutions proposed are partial and the different solutions cannot always be combined. We have organized a Dagstuhl seminar on Progressive Data Analysis and Visualization 87, 139 that acknowledged the harm of this topical separation and devised a research agenda. Aviz will participate in this agenda with specific assets.
Aviz has recently started to design and implement the ProgressiVis language
that is natively progressive 88.
The language relies on a Python interpreter but its execution semantics is
different in the sense that all the operations that would take time to
execute are performed progressively.
The ProgressiVis system touches all the stages of the conceptual data analysis pipeline of
- Progressive language kernel and data management mechanisms
- Progressive algorithms and computation strategies
- Progressive visualizations
- Management of uncertainties, computed from the algorithms and conveyed to the analysts.
Language:
ProgressiVis relies on a Python interpreter that is convenient for quick prototyping but is inefficient. Once the semantics of the language and its core libraries become clearer, we will replace the implementation with a C++ library that will improve performance and allow its integration in other popular data science environments such as R and Julia. We are collaborating with colleagues in the database community to tackle the challenges related to progressive data management 139, 62.
Algorithms:
Existing libraries implementing algorithms are either “eager”, sometimes “online”, and more rarely “streaming”, but very few are compatible with our progressive paradigm. We have started to work in collaboration with the University of Seoul and the University of Delft on the problem of converting existing algorithms into a progressive form. We currently have a running version of approximate k-nearest-neighbors 22, kernel density estimation 22, k-means clustering, multidimensional projection using t-SNE 22, and several other core algorithms. We want to further expand the range of algorithms we can support, and better understand how algorithms could be transformed into their progressive counterpart.
Progressive computation can trade speed, memory, and quality. When analysts want to compute rough estimates of their results quickly, several progressive algorithms offer parameters to control the tradeoffs. For example, our progressive k-nearest-neighbors algorithm 22 allows choosing the number of k-d-trees that influences the memory footprint, accuracy, and speed. Progressive data analysis also uses and adapt streaming algorithms, also called “data sketches” 89, that offer various tradeoffs between speed, memory, and quality.
Visualizations:
Like algorithms need to be adapted or transformed, visualization techniques and user interfaces also need to be adapted to be used in a progressive setting. For the visualization pipeline, including the rendering phase, there has been previous work related to progressive layout computation and progressive rendering. For example, in network visualization, there is a old tradition of using iterative force-directed solvers and showing their results progressively when computing complex graph layouts. We want to generalize this approach to all the visualizations. In the recent years, we have collaborated on work related to the progressive computation of multidimensional projections, including PCA and t-SNE 129, 22, and will continue to improve the scalability of projection methods. Progressive rendering is popular in the real-time computer graphics and gaming domains, but new in visualization. Our colleague Renaud Blanch from Grenoble has started to investigate this problem 73 by designing a rendering engine that can visualize and filter a large amount of data in interactive time, transiently simplifying details when necessary. We will also explore this problem both in the context of direct rendering, when the GPU shares the memory performing the computations, and web-based rendering.
We have also started to explore the problem of requirements for progressive user interfaces 61, leading the community of researchers to understand that progressive systems need to provide effective assessments of the quality of their results to allow analysts to make early decisions. This justifies the next research topic on the management of uncertainties. We have also started to propose new data models for managing aggregated visualizations 109. We will now continue our research to adapt existing visualization techniques and interaction environments to deal with progressive results and parameter steering.
Management of uncertainties
When performing exploratory data analysis on large data, analysts start by trying some algorithms with different parameters until they obtain useful results. Therefore, it is of paramount importance to be able to realize that a specific algorithm or a specific set of parameters are not leading to a useful result and to abort an analysis before it ends to explore other methods. On the other side, in many circumstances when data is “well-behaved”, progressive algorithms achieve very good results quickly, and analysts can make a decision before the end of the algorithms' execution. The assessment of a quality measure related to a computed result is a complex problem, already tackled by other communities (e.g., streaming, approximate queries). Progressive Data Analysis adds two problems: 1) controlling uncertainty during progressive computations, and 2) conveying the results of this uncertainty in a way understandable by analysts, while avoiding possible cognitive biases such as priming and anchoring 111.
To control the uncertainty during the progression of a computation, methods related to Sequential Analysis 90 should be used. They are well-known in the area of clinical trials and have evolved recently to manage large amounts of data while controlling time or quality in Approximate Query Databases such as BlinkDB 58. These approaches should be further adapted for progressive data analysis.
The topic of human cognitive bias will be developed further in
3.2 Physicality in Input and Output
Permanents involved: Pierre Dragicevic, Petra Isenberg, Tobias Isenberg, Jean-Daniel Fekete
In the past few years, researchers at Aviz have begun to investigate beyond-desktop environments for visualization 98, 99, 103, 121. In particular, our team has made important contributions in the areas of large-display visualizations 96, 72, 95, tangible interaction for scientific visualization 65, 63, 67, and data physicalization 104, 108, 106, 120. We will pursue and consolidate this stream of research by focusing on how to leverage physicality in visualization, both as an input channel and as an output channel. We will more specifically i) lay out the scientific foundations for data physicalization; ii) explore physically-situated and physically-embedded visualizations for personal analytics; and iii) study augmented-reality-based scientific visualization.
3.2.1 Scientific Foundations for Data Physicalization
In the next few years, we will work on establishing and consolidating the new area of data physicalization. Data physicalization is an emerging cross-disciplinary research area that examines how computer-supported, interactive physical representations of data, that we call “data physicalizations”, can support cognition, communication, learning, problem solving, and decision-making 106, 44. In contrast to traditional graphical on-screen data visualizations, physicalizations show data in a material form.
Although the research community, and especially the members of Aviz, have made first steps by conducting initial experiments 104 and laying out a research agenda 106,1 the area still lacks a theoretical and empirical foundation that can guide the design of physical data representations, both static and dynamic 118, 119.
Data physicalizations can potentially offer a useful complement to flat (paper-based or screen-based) visualizations due to the ability of physical objects to tap on human skills such as active perception, depth perception, and non-visual senses; they may have the ability to support learning via direct manipulation, and can possibly engage broader audiences. However, there is currently little understanding of the underlying mechanisms, and the exact situations where physicality may be beneficial.
In particular, work in educational psychology and tangible user interfaces has shown that physical manipulation can facilitate cognition, while research on vicarious learning has suggested that people can also learn from observation. However, it is not clear which approach is the most effective, and no study so far has started to examine how previous findings generalize to data physicalizations. We will investigate to what extent manipulable physicalizations can support data-driven cognition compared to non-manipulable physical media such as paper, and to manipulable virtual media (e.g., computer graphics). We will investigate the perception, recollection and interpretation of a data physicalization when people watch it being animated vs. they manipulate it themselves, vs. they watch a third-person manipulate it. We will attempt to conduct this research in collaboration with Barbara Tversky (Professor Emerita of Psychology at Stanford University, Professor of Psychology and Education at Columbia University, and President of the Association for Psychological Science), with whom we have been in close contact.
We will also be working on a taxonomy of physicality, in order to better untangle the factors that distinguish physical from virtual displays, and to help the community develop a coherent terminology that will serve as a thinking and communication tool.
Although we have been involved in research on digital fabrication in the context of data physicalization 134 and despite the new and exciting advances in this domain, we might not pursue this line of research so we can better focus on the research questions mentioned previously. In other words, we will focus more on why build data physicalizations than on the how.
3.2.2 Situated Data Representations for Personal Analytics
In addition to studying physical representations of data, we will study how embedding data visualizations in the physical world can empower people to make effective use of their personal data in a variety of application contexts. People generate data in many areas of daily life (e. g., data generated from shopping cards, fitness and health data). However, these types of personal data are often only exploited by the companies capturing it while they remain unused by the people who “generated” them. Rarely is personal data subjected to an in-depth analysis and used for reflection and decision making.
Personal visual analytics is a new and growing area of research 93, but has mostly focused on desktop and mobile applications. With our work we want to go beyond the traditional platforms of personal data analytics by using situated data visualizations. In a situated data visualization, the data is directly visualized near the physical space, object, or person it originates from 145. For example, a person may attach small e-ink displays embedded with sensors at various locations of their house or their workplace, to better understand their use of space, of equipment, or of energy resources. Or a person who wishes to exercise more may use an augmented reality device to visualize their past running performance in-place. New situated data visualizations like these can surface information in the physical environment—allowing viewers to interpret data in-context and take action in response to it. Because they will make it possible to explore personal data and take action in relevant physical locations, situated visualizations of personal data have the potential to radically transform how people relate to data.
This research will investigate how situated visualizations of personal data can help address problems faced by the general public by investigating a range of research hypotheses and application domains. For example, we will study how augmented reality technology can help surface digital traces of personal data in physical environments and enable people to make more informed decisions. We will also study how small, portable, and situated micro-visualizations can allow people to understand personal data in-place in changing, dynamic, and mobile contexts.
On this topic, we already have an “équipe associée” Inria grant with University of Calgary, and we are currently submitting an ANR PCR proposal in collaboration with Sorbonne Université and Université de Bordeaux.
3.2.3 Visualization using Augmented Reality Devices
Based on past work on the integration of various types of input and output devices for the visualization of inherently three-dimensional spatial data 65, 63, 67, 97, 122, 100, 101, 102, we plan to investigate the use of, in particular, augmented reality (AR) head-mounted displays (HMDs). This combination of stereoscopically projected 3D data which provides a high amount of visual immersion with innovative interaction techniques that facilitate data exploration though immersion that arises from direct manipulation is part of the recently established subfield of visualization research which focuses on immersive analytics 86, 75 and promises to combine benefits of traditional VR-based environments with those that use traditional, touch, or tangible input and used innovative interaction designs. We specifically will focus on AR-based HMDs because they do not prevent us from using traditional data exploration environments such as workstations which are not only familiar to experts but also widely available. The AR HMD, moreover, is an easily maintainable device that does not rely on constant calibration and thus could more easily be integrated into and accepted by existing research facilities than more elaborate VR settings such as CAVEs.
Specifically, we currently have started two projects in this direction. One is a collaboration with particle physicists at the local linear accelerator laboratory as well as researchers at CERN with whom we are exploring an interactive data exploration tool of the experimental data generated at CERN from collisions of protons. In a second project we are working with climate researchers to explore novel collaborative data analysis scenarios in which several experts investigate 3D datasets together with the help of AR HMDs.
3.2.4 Other
In addition to the three major themes previously mentioned, Aviz has also been involved in research on the use of tangible input devices, both to navigate abstract data visualizations 105, 114 and to explore 3D data 101, 68, 66. We will continue this stream of research, possibly applying emerging trends in tangible input device design 91 to data exploration.
3.3 Perception, Cognition and Decision Making
Permanents involved: Steve Haroz, Pierre Dragicevic, Petra Isenberg, Tobias Isenberg, Jean-Daniel Fekete
As we collect increasingly large amounts of data in fields such as climate science, finance, and medicine, the need to understand and communicate that data becomes more important. Data visualizations (e.g., graphs, maps, infographics, etc.) are often used to give an overview of information, however it can be challenging to predict whether these visualizations will be effective before spending resources to develop them. Consequently, researchers make use of experimental methods from visual perception and cognition to study how we perceive and understand visualizations in order to develop generalized guidelines for optimizing effectiveness. While many past studies provide a research groundwork using simple and small visualizations (such as a bar graph with four bars), there has been little research on perception and cognition for more complex visualizations used for large datasets with thousands or millions of elements. Novel techniques researched by Aviz to alleviate complexity can be more effectively used if we understand when and why these techniques become beneficial.
3.3.1 Perceiving the Gist of a Visualization
It would be highly inefficient if users of large data visualizations serially inspected individual visual elemnts. Instead, the visual system allows people to quickly get a visual gist of an overall pattern in the image 136. But how quickly and reliably can we detect these gists when multiple groups or regions in a visualization need to be summarized seperately and compared? What happens to speed and accuracy as more items are added to a visualization? These open questions about the impact of data scale and complexity on visualization perception were discussed in the review article by Szafir, Haroz, Gleicher, and Franconeri 136. To answer these questions, the experiment methods and findings from visual perception can be employed. Specifically, “ensemble coding” is the term used by vision scientists to describe our ability to rapidly perceive simple statistical properties of sets without the need to inspect individual items. Research has shown that we can perceive averages for sets made of simple 59 and complex 135 objects as well as the variance of sets for simple objects 127. But it is not clear if or how we can answer more complex statistical questions about subsets within visualizations, such as:
- How different are trends between groups of line charts?
- Which group's trends are more variable?
- Is the distribution of trends uniform or normally distributed?
For the field of visual perception research, understanding how we make these statistical decisions with collections would be a novel contribution that helps explain how our brain represents and summarizes complex information, how much information is discarded to make rapid judgements, and when biases or accuracy limits arise when working with collections of items.
For the field of data visualization research, understanding the conditions when we can make these statistical judgements and the speed and precision with which we can make them will directly translate to new guidelines for optimal use of visualization for large datasets. Although much visualization software uses settings that rely on design intuition, these results would be the first science-based guidelines for large data visualization and progressive visualization.
3.3.2 Cognitive Limitations for Visually Selecting Subsets in Visualizations
A critical task for analyzing large data mentioned in the previous section is filtering and comparing subsets. But why and when are these filtering tasks difficult? And how can a visualization facilitate the identification of subsets – especially for data with many categories?
How much information we can visually select and attend to and the minimum size of a selection are strongly limited, and this limitation is impacted by the layout of items in an image and the types of visual features and tasks employed 92. Past visual cognition research on the cause of attentional limits 94 generally presumed that we focus on information in a roughly circular region. But subsets in a visualization are often irregularly shaped, and the limitations of attention selection for more chaotic images like visualizations are not understood. Researching how people select irregularly shaped subsets would be a novel contribution to our understanding of visual cognition and could inform how progressive visualization techniques can show datasets such that all subsets can be visually compared.
3.3.3 Illustrative Visualization
We will continue our work in the area of illustrative visualization. This sub-field of visualization takes inspiration from illustrators' decades to centuries of experience in using knowledge from perception and cognition to better portray scientific subject matter. Another input arises from the field of non-photorealistic rendering which has developed numerous techniques of stylizing images and other input data. Traditionally, illustrative visualization has thus been applied primarily to data with a concrete spatial mapping in 2D and, more frequently, in 3D space. Nonetheless, some efforts for understanding the potential benefit of illustrative visualization to non-spatial data have been documented, including some of our own team 80, 60. An interesting aspect in this context is the role of depiction style can play in how visualizations or other forms of depiction are interpreted and understood. For example, we recently investigated the effect of stylization on emotion for images 69, and will extend this work in the future to study how we can use stylization to change the way people perceive, consume, and understand visualizations. One hypothesis to investigate, for example, is that a more hand-drawn depiction style 85 could lead to viewers spending more time with a visualization, and thus take more time to understand and interact with it.
Another main future direction of research in this context is the question of what the role of abstraction is in illustrative visualization 141 as well as visualization in general, and specifically how we can provide dedicated means to control the abstraction being applied to visual representations of data. This means that we need to go beyond seeing abstraction only as a side-product of stylization as it has traditionally been viewed in many approaches in non-photorealistic rendering as well as illustrative visualization to date, and investigate how we can interactively adjust it to provide practitioners with a means to find the best visual representations for a given task. For example, we have investigated this question recently in the context of structural biology 125, 146 and DNA nanostructures 124, 123, but also want to expand this work to other application domains in the future.
3.3.4 Decision Making with Visualizations
Aviz has recently started a novel stream of research on the topic of judgment and decision making with visualizations 78, 77, 79. Human decision making and cognitive biases are important research topics in the fields of psychology, economics and marketing, but until recently, the presence of cognitive biases in visualization-supported decision making has not been investigated. Yet, visualization systems are increasingly used to support decision making: large companies switch to visualization solutions to improve their decisions in a range of areas, where large sums of money or human lives are at stake. More and more, the ultimate goal of visualization is not to understand patterns in the data and get insights as was traditionally assumed, but to make good decisions. In order to fully understand how information visualizations can support decision making, it is important to go beyond traditional evaluations based on data understanding, and study how visualizations interact with human judgment, human heuristics, and cognitive biases.
We will pursue this important stream of research by investigating yet-unexplored areas, such as group decision-making with visualizations, decision making in the presence of uncertainty and incomplete information (in connection with the topics discussed in Sections 3.1 and 3.4.2), and the use of visualizations to support social choice and group decisions in the presence of conflicts of interest. How cognitive biases interact with visual perception is also an important and difficult question that has remained largely unexplored. In terms of application domains, we will be focusing more on evidence-based decision making in everyday life, e.g., how can visualizations be useful (or harmful) when choosing medicines, food products, means of transportation, charity donations, or when electing politicians. For example, a recent study has investigated whether specific infographic designs can lead people to feel more empathy towards suffering populations 74, but with inconclusive or negative results. In collaboration with the University of Campina Grande in Brazil, we are currently investigating designs that we believe are more likely to be effective. We will be evaluating these designs using metrics that are more likely to be correlated with prosocial decision making than empathy, as it has been shown that the emotion or empathy is not always conducive to helping behavior.
3.4 Methodology for Visualization Research
Permanents involved: Petra Isenberg, Steve Haroz, Pierre Dragicevic, Tobias Isenberg
An important aspect of any scientific research is to establish and follow rigorous and effective methodologies for acquiring new knowledge. In the field of Visualization in particular, scientific discourse on the validity, use, and establishment of methodologies is important as the field is highly interdisciplinary, with diverse influences and opinions. It is important to establish, for example, what level of rigor the field should require of its methods, how to choose among established methods and methodologies, and how to best communicate the results of our empirical research. Aviz researchers have in the past been very active in contributing critical reflection on ways to assess different forms of value offered by visualization and visual analytics research and design (e. g., 82, 107, 112, 113, 116, 130, 142). This included work on novel research methods but also existing methods and tools such as statistics. As part of the new team we will focus our efforts on three main topics related to visualization research methodologies.
3.4.1 Promoting and Following Open Research Practices
Fundamental tenants of scientific research are that it is accessible, scrutinizable, and can be built-upon. For visualization research, the low rate of accessibility of both published articles and supporting materials makes it almost impossible to question the claims made in publications or to extend them. We measured the state of some of these issues for the IEEE VIS conference, finding serious problems across every facet of openness 115:
- Open Artifacts: Questioning the veracity of research claims is difficult if the supporting evidence and methods are not available for scrutiny. Without these supporting research artifacts, reviewers and readers cannot thoroughly verify, replicate, or reproduce research, and readers may have difficulty extending and applying research. Such artifacts include but are not limited to: Code, resource files, parameters, sample datasets, and documentation needed to reproduce software, toolkits, or experiment procedures Raw empirical data collected or analyzed to support a paper’s conclusions Analysis code or scripts used to support a paper’s conclusions
- Transparency in Decisions: To clarify distinctions between exploratory and confirmatory research, to reduce hidden flexibility in research (i.e., unreported researcher degrees of freedom 144, and to minimize publications bias, researchers must be educated about the impact of these issues and use approaches such as preregistration and registered reports where appropriate 128115.
- Transparency in statistical reporting: Researchers must report the outcomes of their statistical analyses in a way that does not prompt misinterpretations. This aspect will be further developed in the next subsection.
For these issues to be addressed, educational materials and guidelines need to be written, so researchers have clarity about how to make their research more credible. Moreover, Aviz members are working with the organizing bodies of the visualization research community to establish incentives for making research artifacts and potentially establish minimal requirements for openness in published articles. Meanwhile, it is important to continue measuring and cataloging openness in the field to monitor progress. The goal is to improve the credibility and applicability of the field’s research.
3.4.2 The Communication of Statistics Results
Statistics are tools to help end users accomplish their task. In experimental sciences, to be qualified as usable, statistical tools should help scientists advance scientific knowledge by supporting and promoting the effective communication of research findings. Yet many areas of experimental science have adopted tools that have proven to be poor at supporting these tasks 81. One very common but particularly damaging practice is “dichotomous inference”, i.e., the classification of statistical evidence as either sufficient or insufficient, for example by looking at whether a p-value is above or below the .05 threshold 64. Dichotomous inference encourages practices that distort the scientific literature, such as publication bias, outcome reporting bias, and significance chasing 140. All of these issues contribute to making published studies less trustworthy and less likely to replicate.
A commonly advocated solution is to focus on effect sizes and their interval estimates rather than on p-values. However, interval estimates do not offer a sure protection against dichotomous inference 64. Therefore, many modern statisticians and methodologists urge researchers to think of evidence as gradual rather than binary when interpreting their results, irrespective of the statistical methods used. However, there is a lack of guidance on how to do to so. We will be conducting research on how to design statistical charts that prompt nuanced interpretations, and more generally, charts that convey statistical uncertainty in a honest and transparent manner. The two main targeted populations will be i) experimental scientists (who use research papers as a medium to communicate about scientific findings) and ii) the general population (who use newspapers and online articles to inform themselves about recent science advances). One goal will be to develop guidelines for faithful statistical communication that are evidence-based instead of being based on personal opinions. This research lies at the intersection of statistical cognition 70 and information visualization.
Besides studying visual representations that encourage non-dichotomous inferences, we will pursue one line of research we just started at Aviz, which considers the research paper as a user interface, and seeks to look at how this interface can be improved to help scientists communicate their results in a more transparent manner than using conventional research papers 84.
As a longer-term goal, we are planning to develop conceptual models in order to better understand and better reflect about the diverse phenomena underlying data-driven scientific communication. This includes the process of communicating empirical data between scientists, from scientists to people, and from journalists to people: we will attempt to better understand and describe the entire information pipeline, where information can be lost or distorted, and how to make the pipeline more robust to [self-]deception 83.
3.4.3 Shaping the Scientific Visualization Community
In the past, Aviz researchers have been heavily involved in the organization structure of IEEE visualization conferences, the most prestigious conference in our field, by proposing workshops, tutorials, serving on various organizing committees, steering committees, editorial boards, and even the IEEE Visualization Executive Committee that oversees the whole IEEE Visualization conference. We will continue to do so but will, in addition, be involved in newly created committees that help to restructure the community and prepare it for future growth and inclusivity. We will, in particular, aid the process by providing data collection and analysis services through the vispubdata.org dataset that we are collecting, cleaning, and making available to the community. The dataset has already been used in research (e. g., 117) but also to shape the scientific community by proposing program committee members, new processes, and is currently used by the Visualization Restructuring Committee (ReVISe). We are also involved in the EuroVis community and participate at multiple levels to its organization and management.
4 Application domains
4.1 Natural Sciences
As part of a CORDI PhD project, we collaborate with researchers at CERN on interactive data visualization using augmented reality, with the goal to better understand this new visualization environment and to support the physicists in analysing their 3D particle collision data. As part of another CORDI PhD project, we collaborate with researchers at the German Center for Climate Computation (DKRZ), to better understand collaborative data exploration and interaction in immersive analytics contexts. Finally, as part of the Inria IPL “Naviscope,” we collaborate with researchers at INRAE (as well as other Inria teams) on interactive visualization tools for the exploration of plant embryo development.
4.2 Social Sciences
We collaborate with social science researchers from EHESS Paris on the visualization of dynamic networks; they use our systems (GeneaQuilts 71, Vistorian 131, PAOHVis 29) and teach them to students and researchers. Our tools are used daily by ethnographers and historians to study the evolution of social relations over time. In the social sciences, many datasets are gathered by individual researchers to answer a specific question, and automated analytical methods cannot be applied to these small datasets. Furthermore, the studies are often focused on specific persons or organizations and not always on the modeling or prediction of the behavior of large populations. The tools we design to visualize complex multivariate dynamic networks are unique and suited to typical research questions shared by a large number of researchers. This line of research is supported by the DataIA “HistorIA” project, and by the “IVAN” European project. We also collaborate on the BART initiative, a joint project with IRT-SystemX on the analysis and visualization of blockchain data, in collaboration with economists from Université Paris-Saclay.
4.3 Medicine
We collaborate with CMAP/Polytechnique on the analysis and visualization of CNAM Data “parcours de santé” to help referent doctors and epidemiologists make sense of French health data. In particular, we are working on a subset of the CNAM Data focused on urinary problems, and we have received a very positive feedback from doctors who can see what happens to the patients treated in France vs. what they thought happened through the literature. This project is starting but is already getting a lot of traction from our partners in medicine, epidemiology, and economy of health.
5 Social and environmental responsibility
5.1 Impact of research results
Aviz' work on illustrative visualization (e. g., see Sections 3.3.3 and 8.2) has the potential to be integrated into future teaching materials for students in schools, visitors in museums, or similar.
Aviz' work on anthropographics (Section 8.4) is aiming at improving assistance to populations in need.
Open science: Aviz regularly shares full research material on the repository of the Center for Open Science to facilitate scrutiny, reuse, and replication:
- Antropographic studies 37 – https://
osf. io/ xqae2/ - Anthropographics Design Space 26 – https://
osf. io/ wfgmp/ - Reducing Affective Responses to Surgical Images through Color Manipulation and Stylization 10 – https://
osf. io/ 4pfes/ - Threats of a Replication Crisis in Empirical Computer Science 15 – https://
osf. io/ hkqyt/ - Smart watch survey – https://
osf. io/ nwy2r/ - Readability of micro visualizations on mobile devices – https://
osf. io/ yz8ar/ - User Study of Annotation 3D Placements in Collaborative Augmented Reality Environments – https://
osf. io/ 7a6yr/ - Study on the discovery and selection of cells in 3D plant embryo datasets – https://
osf. io/ yze5n/ - Open Science Tutorial – https://
osf. io/ vfnwp/ - VIS open practice resources – https://
osf. io/ dc6mt/ - Transparency of CHI Research Artifacts – https://
osf. io/ csy8q/
6 Highlights of the year
6.1 Awards
- Jean-Daniel Fekete received four awards:
- IEEE VGTC Technical Achievement Award,
- IEEE VGTC Visualization Academy,
- ACM SIGCHI Academy, and
- AVI 2020 best paper honorable mention award 39.
- Catherine Plaisant received four awards:
- IEEE VGTC Visualization Career Award,
- IEEE VGTC Visualization Academy,
- ACM SIGCHI Lifetime Service Award, and
- ACM SIGMM in Test of Time Awards 2020 (for year 2004).
- Tobias Isenberg
- was named Associate Editor of the year (2019) for Elsevier Computers and Graphics,
- received the IEEE SciVis 2020 Best Poster Design Award (together with Mickaël Sereno), and
- received the IEEE InfoVis 2020 Best Poster Design Award (together with Yuanyang Zhong and Petra Isenberg).
- Petra Isenberg
- received from ARMINER an award for the Top 10 most cited scholars from the top venues of this field in the past 10 years and
- received the IEEE InfoVis 2020 Best Poster Design Award (together with Yuanyang Zhong and Tobias Isenberg).
- Steve Haroz received a ACM SIGCHI 2020 best paper award 38.
- A team of Aviz researchers (including Natkamon Tovanich, Alexis Pister, Gaëlle Richer, Paola Valdivia, Jean-Daniel Fekete, and Petra Isenberg) and colleagues received the VAST Challenge: Outstanding Comprehensive Mini-Challenge 1 Solution.
7 New software and platforms
7.1 New software
7.1.1 Cartolabe
- Name: Cartolabe
- Keyword: Information visualization
- Functional Description: The goal of Cartolabe is to build a visual map representing the scientific activity of an institution/university/domain from published articles and reports. Using the HAL Database, Cartolabe provides the user with a map of the thematics, authors and articles . ML techniques are used for dimensionality reduction, cluster and topics identification, visualisation techniques are used for a scalable 2D representation of the results.
- News of the Year: This year, Cartolabe was applied to the Grand Debat dataset (3M individual propositions from french Citizen, see https://cartolabe.fr/map/debat). The results were used to test both the scaling capabilities of Cartolabe and its flexibility to non-scientific and non-english corpuses. We also Added sub-map capabilities to display the result of a year/lab/word filtering as an online generated heatmap with only the filtered points to facilitate the exploration.
-
URL:
http://
www. cartolabe. fr/ - Contact: Philippe Caillou
- Participants: Philippe Caillou, Jean-Daniel Fekete, Jonas Renault, Anne-Catherine Letournel
- Partners: LRI - Laboratoire de Recherche en Informatique, CNRS
7.1.2 BitConduite
- Name: BitConduite Bitcoin explorer
- Keywords: Data visualization, Clustering, Financial analysis, Cryptocurrency
- Functional Description: BitConduite is a web-based visual tool that allows for a high level explorative analysis of the Bitcoin blockchain. It offers a data transformation back end that gives us an entity-based access to the blockchain data and a visualization front end that supports a novel high-level view on transactions over time. In particular, it facilitates the exploration of activity through filtering and clustering interactions. This gives analysts a new perspective on the data stored on the blockchain.
- Authors: Jean-Daniel Fekete, Petra Isenberg, Christoph Kinkeldey
- Contacts: Jean-Daniel Fekete, Petra Isenberg
7.1.3 PAOHvis
- Name: Parallel Aggregated Ordered Hypergraph Visualization
- Keywords: Dynamic networks, Hypergraphs
- Functional Description: Parallel Aggregated Ordered Hypergraph (PAOH) is a novel technique to visualize dynamic hypergraphs 29. Hypergraphs are a generalization of graphs where edges can connect more than two vertices. Hypergraphs can be used to model co-authorship networks with multiple authors per article, or networks of business partners. A dynamic hypergraph evolves over discrete time slots. A PAOH display represents vertices as parallel horizontal bars and hyperedges as vertical lines that connect two or more vertices. We believe that PAOH is the first technique with a highly readable representation of dynamic hypergraphs without overlaps. It is easy to learn and is well suited for medium size dynamic hypergraph networks such as those commonly generated by digital humanities projects - our driving application domain (see Fig. 2).
-
URL:
https://
aviz. fr/ paohvis - Contacts: Paola Tatiana Llerena Valdivia, Jean-Daniel Fekete
7.1.4 AR Collaborative Visualization
- Name: AR Collaborative Visualization
- Keywords: Augmented reality, Collaborative science, Android
- Functional Description: Allows to look at VTK datasets using AR-HMD (Microsoft HoloLens) in multi-users environments (i.e., one headset per user). A Multi-touch tablet is provided per user to manipulate the environment.
- Contact: Tobias Isenberg
7.2 New platforms
AVIZ members are making available for research a dataset of IEEE VIS publications at http://
AVIZ members are contributing to making available for research a dataset of IEEE VIS images at https://
8 New results
8.1 Visualization and Clustering of Hypergraphs
Participants: Jean-Daniel Fekete, Paola Valdivia, Alexis Pister, Catherine Plaisant, Paolo Buono.
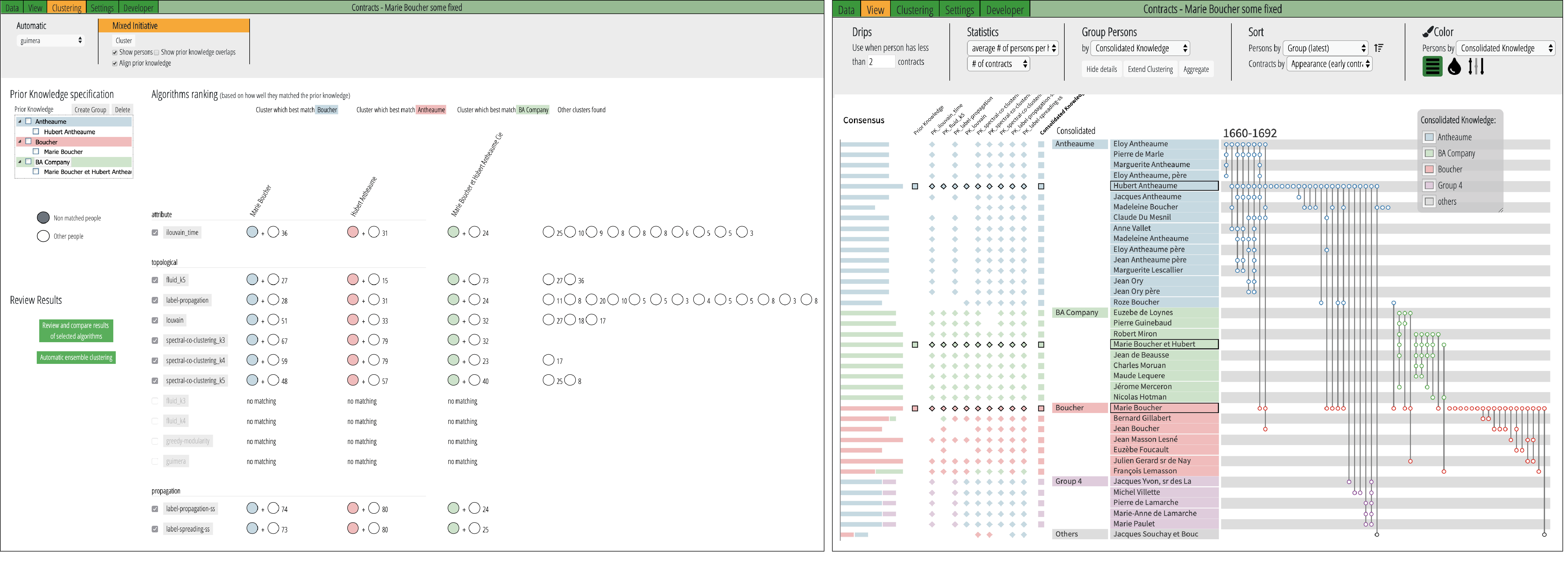
We propose a new paradigm, called PK-clustering 27, to help social scientists create meaningful clusters in social networks. Many clustering algorithms exist but most social scientists find them difficult to understand, and tools do not provide any guidance to choose algorithms, or to evaluate results taking into account the prior knowledge of the scientists. Our work introduces a new clustering paradigm and a visual analytics user interface that address this issue. It is based on a process that 1) captures the prior knowledge of the scientists as a set of incomplete clusters, 2) runs multiple clustering algorithms (similarly to clustering ensemble methods),3) visualizes the results of all the algorithms ranked and summarized by how well each algorithm matches the prior knowledge, 5)evaluates the consensus between user-selected algorithms and 6) allows users to review details and iteratively update the acquired knowledge. We believe our clustering paradigm offers a novel constructive method to iteratively build knowledge while avoiding being overly influenced by the results of often-randomly selected black-box clustering algorithms. PK-clustering relies the PAOHVis representation 29 for dynamic hypergraphs.
This work is conducted in the context of the HistorIA project funded by DataIA, and of the IVAN project.
More on the project web page https://
8.2 Illustrative visualization of the genome
Participants: Sarkis Halladjian, Haichao Miao, David Kouřil, M. Eduard Gröller, Ivan Viola, Tobias Isenberg.

We present ScaleTrotter, a conceptual framework for an interactive, multi-scale visualization of biological mesoscale data and, specifically, genome data. ScaleTrotter allows viewers to smoothly transition from the nucleus of a cell to the atomistic composition of the DNA, while bridging several orders of magnitude in scale. The challenges in creating an interactive visualization of genome data are fundamentally different in several ways from those in other domains like astronomy that require a multi-scale representation as well. First, genome data has intertwined scale levels—the DNA is an extremely long, connected molecule that manifests itself at all scale levels. Second, elements of the DNA do not disappear as one zooms out—instead the scale levels at which they are observed group these elements differently. Third, we have detailed information and thus geometry for the entire dataset and for all scale levels, posing a challenge for interactive visual exploration. Finally, the conceptual scale levels for genome data are close in scale space, requiring us to find ways to visually embed a smaller scale into a coarser one. We address these challenges by creating a new multi-scale visualization concept using a scale-dependent camera model that controls the visual embedding of the scales into their respective parents, the rendering of a subset of the scale hierarchy, and the location, size, and scope of the view. In traversing the scales, ScaleTrotter is roaming between 2D and 3D visual representations that are depicted in integrated visuals. We discuss, specifically, how this form of multi-scale visualization is a consequence of the specific characteristics of the genome data and describe its implementation. Finally, we discuss the implications of our work to the general illustrative depiction of multi-scale data.
In on-going work we are also exploring a spatial control of abstraction for illustrative visualization. This means that representative examples for the structural organization of the genome at all the scale levels, which are only visible one-at-a-time in the ScaleTrotter approach, become visible and seamlessly connected in a single view.
8.3 Visualization for monitoring and exploration of the Bitcoin blockchain
Participants: Natkamon Tovanich, Nicolas Heulot, Jean-Daniel Fekete, Nicolas Soulié.
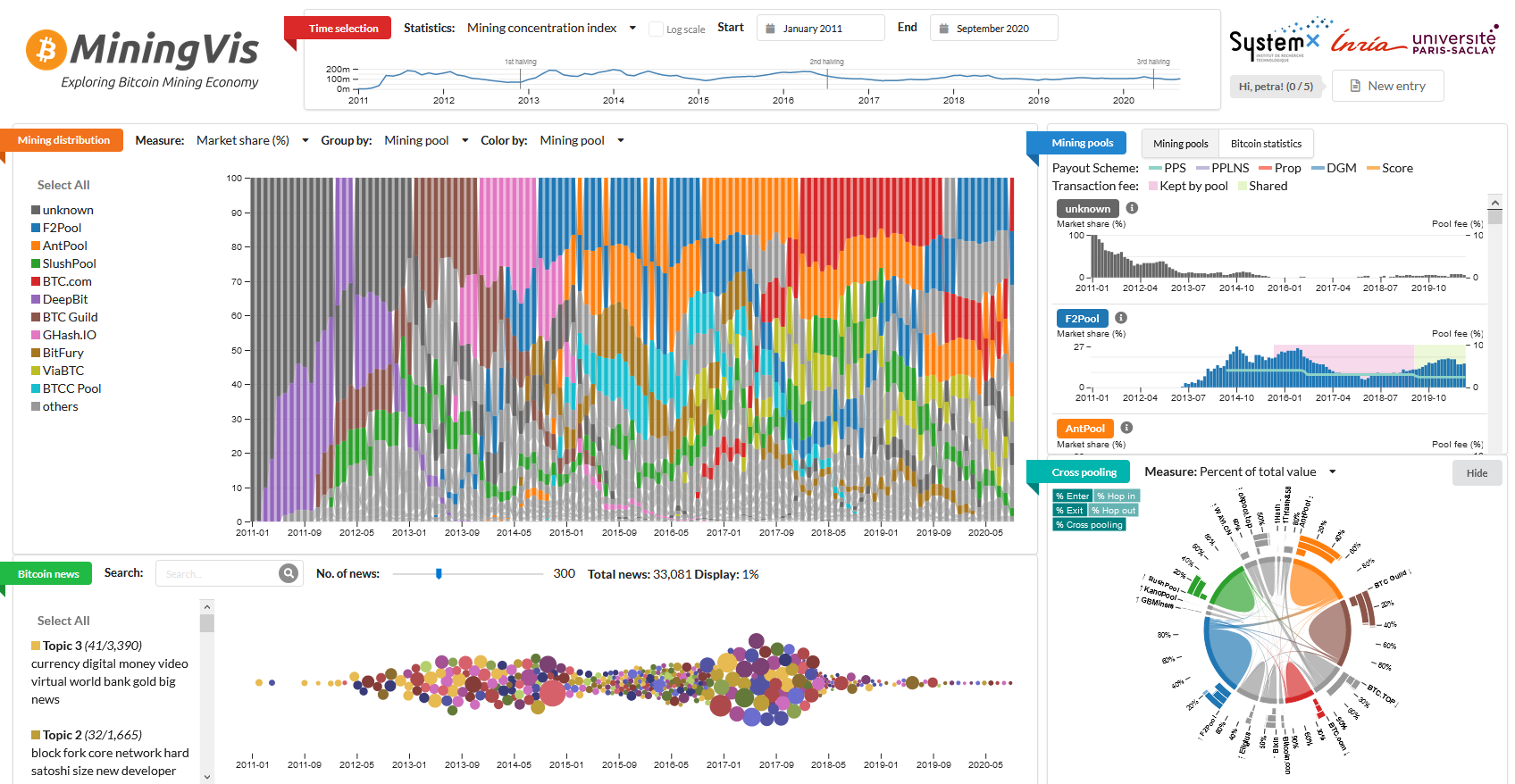
In the last year we actively worked on visual analytics tools to support the analysis of the Bitcoin blockchain. We focused on Bitcoin mining. Mining blocks is a critical component of the Bitcoin ecosystem, helping to keep the system secure, valid, and stable. At the same time, mining is a resource-intensive activity that continues to get more and more difficult. Mining pools have emerged to address this issue and to ensure a more stable and predictable income by sharing computing power. Yet, increased centralization of the mining power is also not without dangers (e.g., the 51% attack), and, thus, it is important to better understand and analyze mining pool activities in Bitcoin. We made several contributions: an extensive data collection on Bitcoin mining pools, the development of two custom visualizations and a comprehensive tool called MiningVis, a first exploratory data analysis leading to hypotheses and documented activities about pools’ main features such as market share, reward rules, or location.
8.4 Visualizations for promoting empathy and compassion
Participants: Luis Morais, Yvonne Jansen, Nazareno Andrade, Pierre Dragicevic.
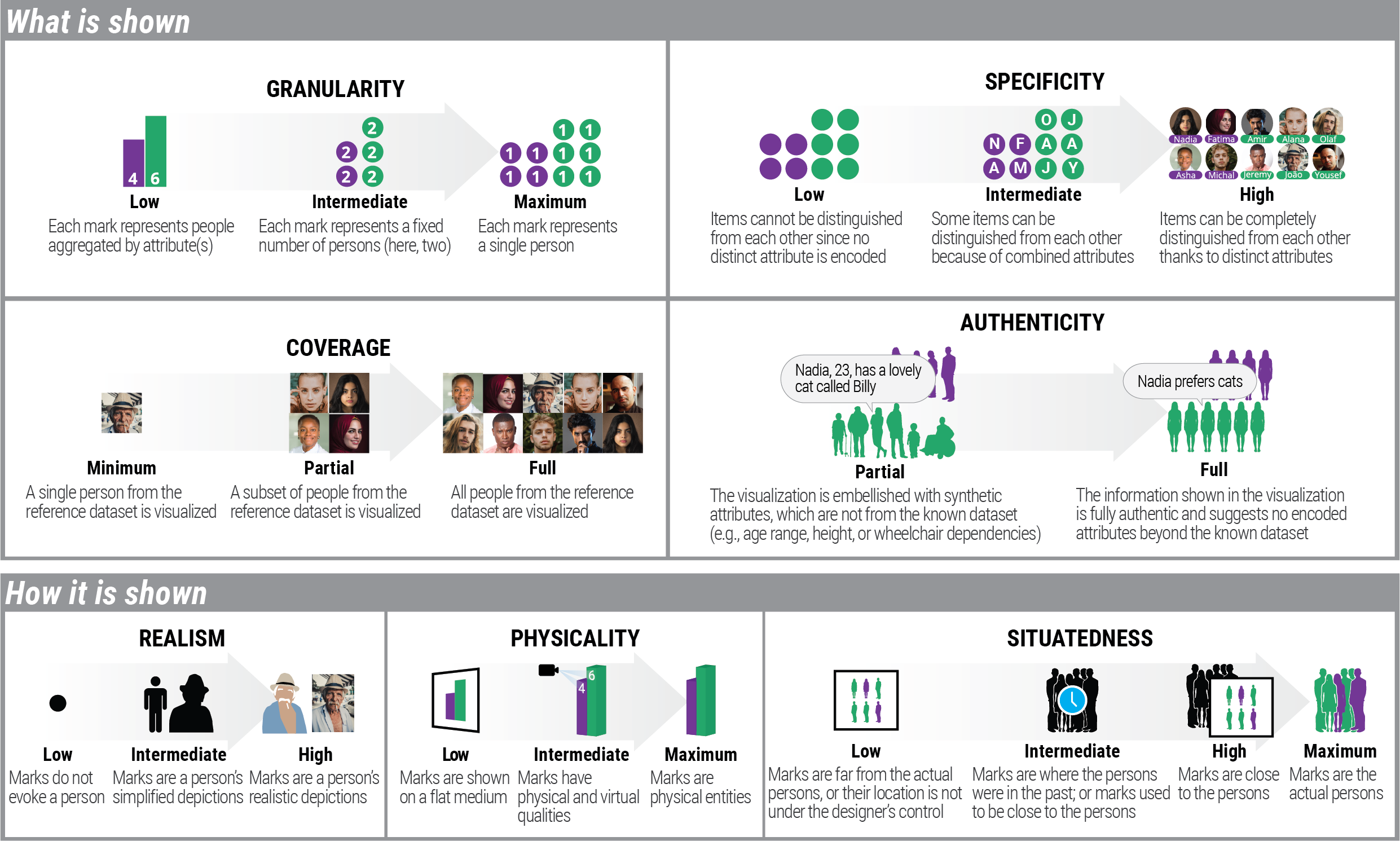
When showing data about people, visualization designers and data journalists often use design strategies that presumably help the audience relate to those people. The term “anthropographics” has been recently coined to refer to this practice and the resulting visualizations. Anthropographics is a rich and growing area, but the work so far has remained scattered. Despite preliminary empirical work and a few web essays written by practitioners, there is a lack of clear language for thinking about and communicating about anthropographics. In an article recently published at IEEE TVCG 26, we addressed this gap by introducing a conceptual framework and a design space for anthropographics. Our design space consists of seven elementary design dimensions that can be reasonably hypothesized to have some effect on prosocial feelings or behavior (Figure 5). It extends a previous design space and is informed by an analysis of 105 visualizations collected from newspapers, websites, and research papers. We used our conceptual framework and design space to discuss trade-offs, common design strategies, as well as future opportunities for design and research in the area of anthropographics. Our corpus of anthropographic visualizations can be explored at https://
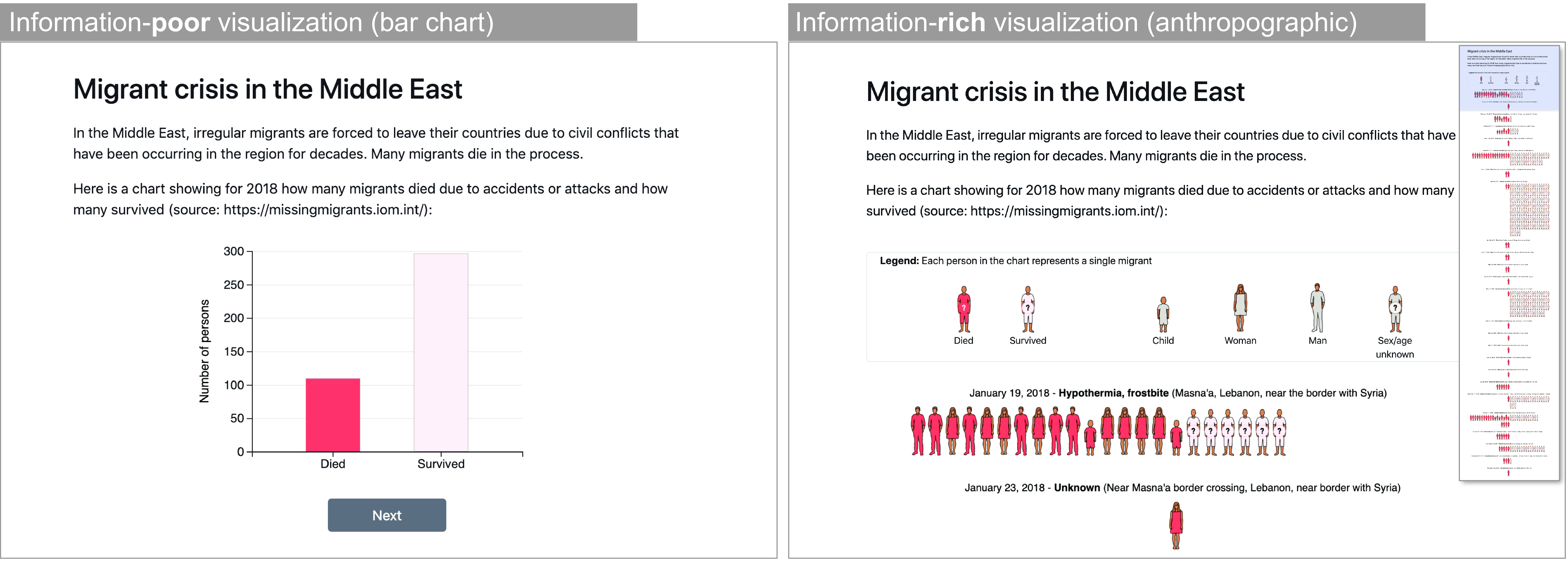
Empirical studies have recently examined whether anthropographics promote empathy, compassion, or the likelihood of prosocial behavior, but findings have been inconclusive so far. In an article recently published at ACM CHI 37, we contributed a detailed overview of past experiments, and two new experiments that use large samples and a combination of design strategies to maximize the possibility of finding an effect. We tested an information-rich anthropographic against a simple bar chart (Figure 6), asking participants to allocate hypothetical money in a crowdsourcing study. We found that the anthropographic had, at best, a small effect on money allocation. Such a small effect may be relevant for large-scale donation campaigns, but the large sample sizes required to observe an effect and the noise involved in measuring it make it very difficult to study in more depth. We discussed implications for our findings, such as the importance of testing alternative anthropographic design strategies as well as using alternative methodologies, such as real money donation tasks or observations in the field, for example, by testing alternative designs on the website of a real charity. Data and code are available at https://
8.5 Mobile Data Visualization
Participants: Petra Isenberg, Alaul Islam, Tanja Blascheck, Anastasia Bezerianos, Bongshin Lee, Eun Kyoung Choe.

With an increasing use of mobile devices in everyday life, it is important to understand how to design data visualizations for small displays. A nuanced understanding is especially important since existing guidelines for visualization and data interaction design do not transfer well to mobile devices. Throughout the year several projects of the team contributed to an increased understanding of mobile data visualization design.
In an viewpoints article we argued that the visualization research community can and should reach broader audiences beyond data-savvy groups of people, because these audiences could also greatly benefit from visual access to data. In this paper, we discussed four research topics—personal data visualization, data visualization on mobile devices, inclusive data visualization, and multimodal interaction for data visualization — that, individually and collaboratively, would help us reach broader audiences with data visualization, making data more accessible.
In a project led by PhD student Alaul Islam we conducted a
survey with 237 smartwatch wearers, and assess the types of data
and representations commonly displayed on watch faces. We found
a predominant display of health & fitness data, with icons accompa-
nied by text being the most frequent representation type. Combining
these results with a further analysis of online searches of watch
faces and the data tracked on smartwatches that are not commonly
visualized, we discuss opportunities for visualization research. Sup-
plementary material for this study is available at https://
In another online study we compare the efficacy of animated and small multiples variants of scatterplots on mobile phones for comparing trends in multivariate datasets. Visualization is increasingly prevalent in mobile applications and mobile-first websites, yet there is little prior visualization research dedicated to small displays. In this paper, we build upon previous experimental research carried out on larger displays that assessed animated and non-animated variants of scatterplots. Incorporating similar experimental stimuli and tasks, we conducted an experiment where 96 crowdworker participants performed nine trend comparison tasks using their mobile phones. We found that those using a small multiples design consistently completed tasks in less time, albeit with slightly less confidence than those using an animated design. The accuracy results were more task-dependent, and we further interpret our results according to the characteristics of the individual tasks, with a specific focus on the trajectories of target and distractor data items in each task. We identified cases that appeared to favor either animation or small multiples, providing new questions for further experimental research and implications for visualization design on mobile devices. Lastly, we provided a reflection on our evaluation methodology.
9 Bilateral contracts and grants with industry
9.1 Bilateral contracts with industry
- Participants: Yuheng Feng, Jean-Daniel Fekete, Alejandro Ribes. Project title: Visual Sensitivity Analysis for Ensembles of Curves: The goal of this project is to investigates new progressive methods to compute PCA over large amounts of time-series in interactive time.
10 Partnerships and cooperations
10.1 International initiatives
10.1.1 Inria associate team not involved in an IIL
SEVEN
- Title: Situated and Embedded Visualization ENvironments
- Duration: 2018 - 2020
- Coordinator: Petra Isenberg
-
Partners:
- ILab, University of Calgary (Canada)
- Inria contact: Petra Isenberg
- Summary: The goal of our joint work is to explore the potential of situated data visualizations to address the limitations of traditional platforms of data analytics. In a situated data visualization, the data is directly visualized next to the physical space, object, or person it refers to. Situated data visualizations such as these have many potential benefits: they can surface information in the physical environment and allow viewers to interpret data in-context; they can be tailored to highlight spatial connections between data and the physical environment, making it easier to make decisions and act on the physical world in response to the insights gained; and they can embed data into physical environments so that it remains visible over time, making it easier to monitor changes, observe patterns over time and collaborate with other people. Although there have been some isolated research contributions on situated visualization prototypes, the applications considered so far remain very limited, the general problem space has remained mostly unexplored, and little guidance is available on how to design and build such systems. Our associate team effort is focused on establishing situated and embedded visualization research within the domain of visualization, showing the potential of situated visualizations, and grounding specific designs in a broader conceptual understanding.
10.1.2 Inria international partners
Declared Inria international partners
- University of Calgary, Canada: SEVEN Project (see 10)
- University of Stuttgart, Germany: MicroVis project
- Technical University of Vienna, Austria: ILLUSTRARE project, IVAN project
- King Abdullah University of Science and Technology, Saudi-Arabia: ILLUSTRARE project
- EPFL, Lausanne, Switzerland: IVAN project
Informal international partners
- Microsoft Research, USA: Bongshin Lee
- University of Maryland, USA: Catherine Plaisant (Inria International Chair), Leilani Battle, Eun Kyoung Choe
- University of Bari, Italy: Paolo Buono
- Universidade Federal de Campina Grande Campina Grande, Brazil: Nazareno Andrade
- University of Cantebury, Christchurch, New Zealand: Andy Cockburn
- Shandong University, Qingdao, China: Yunhai Wang
- University of Edinburgh, UK: Benjamin Bach
- Simon Fraser University, Canada: Sheelagh Carpendale
- Technische Universität Dresden, Germany: Raimund Dachselt
- Ohio State University, USA: Jian Chen, Han-Wei Chen
- University of Stuttgart, Germany: Michael Sedlmair
- University of Granada, Spain: Domingo Martin
10.2 European initiatives
10.2.1 Collaborations in European programs, except FP7 and H2020
- Program: ANR PRCI
- Project acronym: MicroVis
- Project title: Micro visualizations for pervasive and mobile data exploration
- Duration: 11/2019 – 08/2022
- Coordinator: Petra Isenberg
- Other partners: University of Stuttgart
- Abstract: The goal of this joint Franco-German project is to study very small data visualizations, micro visualizations, in display contexts that can only dedicate minimal rendering space for data representations. We will study human perception of and interaction with micro visualizations given small as well as complex data. The increasing demand for data visualizations on small mobile devices such as fitness tracking armbands, smart watches, or mobile phones drives our research. Given this usage context, we focus on situations in which visualizations are used “on the go,” while walking, riding a vehicle, or running. It is still unclear to which extent our knowledge of desktop-sized visualizations transfers to contexts that involve minimal display space, diverse viewing angles, and moving displays.
- Program: 2016 FWF–ANR Call for French-Austrian Joint Projects
- Project acronym: ILLUSTRARE
- Project title: Integrative Visual Abstraction of Molecular Data
- Duration: 48 months, extended until the end of June 2021
- Coordinator: Tobias Isenberg and Ivan Viola
- Other partners: TU Wien, Austria; King Abdullah University of Science and Technology, Saudi-Arabia
- Abstract: The essential building block of visualization is the phenomenon of visual abstraction. While visual abstraction is intuitively understood, there is no scientific theory associated with it that would be useful in the visualization synthesis process. Our central aim of this project is thus to gain better understanding of the visual abstraction characteristics. We lay down a hypothetical initial basis of theoretical foundations of visual abstractions in the proposal. We hypothesize that visual abstraction is a multidimensional phenomenon that can be spanned by axes of abstraction. Besides abstractions associated with a static structure we take a closer look at abstractions related to dynamics, procedures, and emergence of the structure. We also study abstraction characteristics related to multi-scale phenomena defined both in space and in time. This hypothetical basis is either supported or rejected by means of exemplary evidence from the specific application domain of structural biology. Structural biology data is very complex, it includes the aspect of emergence and it is defined over multiple scales. Furthermore, abstraction has led to key discoveries in biology, such as the organization of the DNA. We study the multiscale visual abstraction characteristics on the visualization of long nucleic strands and the abstractions that convey emerging phenomena on visualization of molecular machinery use cases. From these two fields we work toward a theory of visual abstraction in a bottom-up manner, investigating the validity of the theory in other application domains as well.
- Program: CHIST-ERA
- Project acronym: IVAN
- Project title: Interactive and Visual Analysis of Networks
- Duration: May 2018 - April 2021
- Coordinator: Dr. Torsten Möller, Uni Wien, Austria
- Other partners: EPFL, Switzerland, Inria France, Uni Wien, Austria
-
Abstract:
The main goal of IVAN is to create a visual analysis system for the exploration of dynamic or time-dependent networks (from small to large scale). Our contributions will be in three principal areas:
novel algorithms for network clustering that are based on graph harmonic analysis and level-of-detail methods;
the development of novel similarity measures for networks and network clusters for the purpose of comparing multiple network clusterings and the grouping (clustering) of different network clusterings; and
a system for user-driven analysis of network clusterings supported by novel visual encodings and interaction techniques suitable for exploring dynamic networks and their clusterings in the presence of uncertainties due to noise and uncontrolled variations of network properties.
Our aim is to make these novel algorithms accessible to a broad range of users and researchers to enable reliable and informed decisions based on the network analysis.
10.3 National initiatives
- Program: ANR PRC (ANR-19-CE33-0012)
- Project acronym: EMBER
- Project title: Situated Visualizations for Personal Analytics
- Duration: 2020 – 2023. Total funding: 712 k€
- Coordinator: Pierre Dragicevic
- Other partners: Inria Bordeaux, Sorbonne Université
-
Abstract:
The Ember project will study how situated data visualization systems can help people use their personal data (e.g., fitness and physiological data, energy consumption, banking transactions, online social activity,…) for their own benefit. Although personal data is generated in many areas of daily life, it remains underused by individuals. Rarely is personal data subjected to an in-depth analysis and used to inform daily decisions. This research aims to empower individuals to improve their lives by helping them become advanced consumers of their own data. This research builds on the area of personal visual analytics, which focuses on giving the general public effective and accessible tools to get insights from their own data. Personal visual analytics is a nascent area of research, but has so far focused on scenarios where the data visualization is far removed from the source of the data it refers to. The goal of this project is to address the limitations of traditional platforms of personal data analytics by exploring the potential of situated data visualizations. In a situated data visualization, the data is directly visualized near the physical space, object, or person it refers to. Situated data visualizations have many potential benefits: they can surface information in the physical environment and allow viewers to interpret data in-context; they can be tailored to highlight spatial connections between data and the physical environment, making it easier to make decisions and act on the physical world in response to the insights gained; and they can embed data into physical environments so that it remains visible over time, making it easier to monitor changes, observe patterns over time and collaborate with other people. Website: http://
ember. inria. fr/.
Other projects:
- DATAIA project HistorIA “Computational social sciences and information visualization join forces to explore and analyze large historical databases”. Duration: 36 months. Total funding: 240k€. Partners: Inria Saclay, Telecom Paris. Coordinators: Jean-Daniel Fekete, Christophe Prieur.
- Naviscope Inria Project Lab on Image-guided NAvigation and VIsualization of large data sets in live cell imaging and microSCOPy; collaboration with several Inria project teams and external collaborators; this grant supports a PhD position and funds travel and equipment.
11 Dissemination
11.1 Promoting scientific activities
- Jean-Daniel Fekete: Chair of the Eurovis Best PhD Award 2018-2021
- Jean-Daniel Fekete: Jury member of Prix de thèse Gilles Kahn 2020
Member of the organizing committees
- Pierre Dragicevic: alt.chi co-chair at ACM CHI 2021.
- Petra Isenberg: Member of the IEEE Visualization reVISe Committee
Member of Conference Program Committees
- Jean-Daniel Fekete: Eurovis 2020
- Petra Isenberg: IEEE InfoVis 2020
- Tobias Isenberg: IEEE SciVis 2020, BELIV 2020
Reviewer
- Tobias Isenberg: ISMAR 2020, IEEE SciVis 2020, UIST 2020
- Petra Isenberg: ACM CHI 2020, EuroVA 2020, EuroVis 2020, MobileHCI 2020
Too many to mention.
11.1.1 Journal
- Jean-Daniel Fekete: Member of the Publication Board of Eurographics
- Jean-Daniel Fekete: Member of the Scientific Committee of the French journal "Humanités Numériques"
Member of the editorial boards
- Jean-Daniel Fekete: Associate Editor in Chief of IEEE Transactions on Visualization and Computer Graphics (TVCG)
- Tobias Isenberg: Associate Editor for Elsevier Computers & Graphics (C&G)
- Pierre Dragicevic: Member of the editorial board of the Journal of Perceptual Imaging (JPI)
- Pierre Dragicevic: Member of the editorial board of the Springer Human–Computer Interaction Series (HCIS).
- Petra Isenberg: Associate Editor for IEEE Transactions on Visualization and Computer Graphics (TVCG)
- Petra Isenberg: Associate Editor in Chief at IEEE Computer Graphics and Applications
Reviewer - reviewing activities
- Tobias Isenberg: Computer Graphics Forum (CGF), IEEE Transactions on Visualization and Computer Graphics (TVCG)
- Petra Isenberg: Computers and Graphics
11.1.2 Invited talks
- Jean-Daniel Fekete: Keynote of the Chinese visual computing summer school, "Progressive data analysis: a new language paradigm for scalability in exploratory data analysis", virtual, July 17, 2020
- Jean-Daniel Fekete: Seminar at Inria Saclay, "Demandez le programme", "Progressivis", Palaiseau, Feb. 27, 2020
- Petra Isenberg: Vis Evaluation – Moving into the Next Decade; Panel statement given at the Beliv Workshop 2020, held virtually; October 2020
- Petra Isenberg: When Visualization meets HCI; Keynote at the Mensch und Computer 2020 Conference (held virtually); September 2020
11.1.3 Leadership within the scientific community
- Tobias Isenberg: Steering Committee for ACM/EG Expressive; Steering Committee for BELIV workshop series
- Petra Isenberg: Vice-chair of the IEEE Visualization Steering Committee; Steering Committee Member for BELIV workshop series
11.1.4 Research administration
- Pierre Dragicevic: member of the CCSU (Commission Consultative de Spécialistes de l'Université Paris-Saclay)
- Pierre Dragicevic: member of the Conseil de Labo LISN
- Pierre Dragicevic: co-chair of the IID axis of the Labex Digicosme
- Pierre Dragicevic: member of the CER (Comité d'Éthique de la Recherche) Paris-Saclay
- Petra Isenberg: Member of the Commission de Developpement Technologique, Inria
11.2 Teaching - Supervision - Juries
11.2.1 Teaching
- Master: Petra Isenberg, Interactive Information Visualization, 21h en equivalent, niveau (M1, M2), Univeristé Paris-Saclay, France.
- Master: Petra Isenberg, Graphisme et Visualisation, 24h en equivalént TD, niveau (M2), Polytech Paris-Saclay, France.
- Master: Petra Isenberg, Visual Analytics, 48h equivalent, niveau (M2), CentraleSupelec, France.
- Licence : Tobias Isenberg, “Introduction to Computer Graphics”, 18h en équivalent TD, L3, Polytech Paris-Saclay, France.
- Master: Tobias Isenberg, “Photorealistic Rendering/Advanced Computer Graphics”, 28h en équivalent TD, M2, Polytech Paris-Saclay, France.
- Master: Tobias Isenberg, “Illustrative Visualization”, 6h en équivalent TD, M2, ENSTA, France.
- Master: Jean-Daniel Fekete, Scalability in Visual Analytics, 3h, niveau (M2), CentraleSupelec, France.
- Training: Jean-Daniel Fekete: Crash course on HCI and Visualization, IRT SystemX, 6h
11.2.2 Supervision
- PhD in progress: Marie Destandau, Path-Based Interactive Visual Exploration of Knowledge Graphs, Université Paris-Saclay, defense planned for December 2020, co-supervised by Emmanuel Pietriga and Jean-Daniel Fekete.
- PhD in progress: Alexis Pister, Exploration, analyse, interprétabilité de larges réseaux historiques, Université Paris-Saclay, defense planned for 2022, co-supervised by Jean-Daniel Fekete and Christophe Prieur, Telecom Paris.
- PhD in progress: Jiayi Hong, Interactive Visualization and Classification of Temporal Developments in 3D Datasets, Univ. Paris-Saclay, defense planned for December 2022, Tobias Isenberg.
- PhD in progress: Mickaël Sereno, Collaborative Data Exploration and Discussion Supported by AR, Univ. Paris-Saclay, defense planned for December 2021, Tobias Isenberg.
- PhD completed: Xiyao Wang, Augmented Reality Environments for the Interactive Exploration of 3D Data, Univ. Paris-Saclay, defended successfully December 16, 2020, Tobias Isenberg.
- PhD completed: Sarkis Halladjian, Spatially Integrated Abstraction of Genetic Molecules, Univ. Paris-Saclay; defended successfully December 14, 2020, Tobias Isenberg.
- PhD in progress: Mohamad Alaul Islam: MicroVisualization for mobile and ubiquitous data exploration, Université Paris-Saclay, defense planned for 2022, Petra Isenberg and Jean-Daniel Fekete.
- PhD in progress: Natkamon Tovanich: Blockchain Visual Analytics, defense planned for 2021, Université Paris-Saclay, Petra Isenberg and Jean-Daniel Fekete.
- PhD in progress: Lijie Yao: Visualization in Motion, defense planned for 2023, Université Paris-Saclay, Petra Isenberg and Anastasia Bezerianos.
11.2.3 Juries
- Jean-Daniel Fekete: Vincent Raveneau, "Interaction in Progressive Visual Analytics. An application to progressive sequential pattern mining", Université de Nantes, Nov. 4, 2020
- Jean-Daniel Fekete: Anastasia Bezerianos, HdR, "Increasing the bandwidth of interactive visualizations using complex display environments and targeted designs", Université Paris-Saclay, Jul. 2nd, 2020
- Jean-Daniel Fekete: Robin Cura, "Modéliser des systèmes de peuplement en interdisciplinarité. Co-construction et exploration visuelle d'un modèle de simulation", Université Paris 1, Mar. 6, 2020
- Petra Isenberg: Paul Lapides, “Information Visualization for Exploration and Self-Reflection in Social Media”, University of Calgary, 2020
- Petra Isenberg: Fern Bishop, “Investigating the Support of Visualization Creation Activities with Children” University of St. Andrews, 2020
11.3 Popularization
11.3.1 Articles and contents
- Guest post by Steve Haroz on “Statistical Modeling, Causal Inference, and Social Science" — "IEEE’s Refusal to Issue Corrections”. https://
statmodeling. stat. columbia. edu/ 2020/ 12/ 10/ieees-refusal-to-issue-corrections/ - Guest post by Steve Haroz on “Statistical Modeling, Causal Inference, and Social Science" — "Update on IEEE’s refusal to issue corrections”. https://
statmodeling. stat. columbia. edu/ 2020/ 12/ 23/ update-on-ieees-refusal-to-issue-corrections/ - Article “Arkangel dans Black Mirror : la réalité diminuée” by Lonni Besançon, Amir Semmo, Tobias Isenberg, and Pierre Dragicevic in Interstices 57https://
interstices. info/ arkangel-dans-black-mirror-la-realite-diminuee/ - Blog post on “Le divulgâcheur Arkangel de Black Mirror” in Le Monde's binaire blog about work by Lonni Besançon, Amir Semmo, Tobias Isenberg, and Pierre Dragicevic 10https://
www. lemonde. fr/ blog/ binaire/ 2020/ 04/ 14/ le-divulgacheur-arkangel-de-black-mirror/ - Blog post on “Can Graphic Content Inform Without the Shock-factor?” in Wiley's researcher blog series about work by Lonni Besançon, Amir Semmo, Tobias Isenberg, and Pierre Dragicevic 10https://
www. wiley. com/ network/ researchers/ researcher-blogs/ can-graphic-content-inform-without-the-shock-factor - Pierre Dragicevic and Yvonne Jansen: the data physicalization wiki (http://
dataphys. org/) and the List of Physical Visualizations and Related Artefacts (http:// dataphys. org/ list/, 600 weekly visits) are continuously being updated.
11.3.2 Education
- Petra Isenberg: Interview for the Linkedin Data visualization Series
12 Scientific production
12.1 Major publications
- 1 inproceedingsDatabase Benchmarking for Supporting Real-Time Interactive Querying of Large DataSIGMOD '20 - International Conference on Management of DataProceedings of the 2020 ACM SIGMOD International Conference on Management of DataPortland, OR, United StatesACMJune 2020, 1571-1587
- 2 articleGlanceable Visualization: Studies of Data Comparison Performance on SmartwatchesIEEE Transactions on Visualization and Computer Graphics251January 2019, 616--629
- 3 article Cartolabe: A Web-Based Scalable Visualization of Large Document Collections IEEE Computer Graphics and Applications 2020
- 4 articleScaleTrotter: Illustrative Visual Travels Across Negative ScalesIEEE Transactions on Visualization and Computer Graphics261January 2020, 654-664
- 5 inproceedings Opportunities and Challenges for Data Physicalization Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI) ACM New York, NY, United States April 2015
- 6 inproceedings Can Anthropographics Promote Prosociality? A Review and Large-Sample Study CHI 2021 - Conference on Human Factors in Computing Systems Yokohama / Virtual, Japan May 2021
- 7 article Integrating Prior Knowledge in Mixed Initiative Social Network Clustering IEEE Transactions on Visualization and Computer Graphics October 2020
- 8 unpublishedTransparency of CHI Research Artifacts: Results of a Self-Reported SurveyNovember 2020, working paper or preprint
- 9 inproceedings Towards an Understanding of Augmented Reality Extensions for Existing 3D Data Analysis Tools CHI '20 - 38th SIGCHI conference on Human Factors in computing systems Honolulu, United States April 2020
12.2 Publications of the year
International journals
International peer-reviewed conferences
Conferences without proceedings
Scientific book chapters
Reports & preprints
Other scientific publications
12.3 Other
Scientific popularization
12.4 Cited publications
- 58 inproceedingsKnowing when You'Re Wrong: Building Fast and Reliable Approximate Query Processing SystemsProceedings of the 2014 ACM SIGMOD International Conference on Management of DataSIGMOD '14New York, NY, USASnowbird, Utah, USAACM2014, 481--492URL: http://doi.acm.org/10.1145/2588555.2593667
- 59 articleSeeing Sets: Representation by Statistical PropertiesPsychological Science1222001, 157--162URL: http://www.jstor.org/stable/40063604
-
60
inproceedings
Illustrative Data Graphics in 18
–19 Century Style: A Case Study' Posters at the IEEE Conference on Visualization (IEEE VIS, October 13--18, Atlanta, GA, USA) 2013 - 61 articleSteering the Craft: UI Elements and Visualizations for Supporting Progressive Visual AnalyticsComputer Graphics Forum363June 2017, 491--502
- 62 inproceedings Evaluating Visual Data Analysis Systems: A Discussion Report HILDA'18: Workshop on Human-In-the-Loop Data Analytics Houston, TX, United States June 2018
- 63 inproceedingsPressure-Based Gain Factor Control for Mobile 3D Interaction using Locally-Coupled DevicesCHI 2017 - ACM CHI Conference on Human Factors in Computing SystemsNew YorkACM2017, 1831--1842
- 64 inproceedings The Continued Prevalence of Dichotomous Inferences at CHI CHI '19 Extended Abstracts on Human Factors in Computing Systems Glasgow, United Kingdom May 2019
- 65 articleHybrid Tactile/Tangible Interaction for 3D Data ExplorationIEEE Transactions on Visualization and Computer Graphics231January 2017, 881--890
- 66 inproceedings Interactive 3D Data Exploration Using Hybrid Tactile/Tangible Input Journées Visu 2017 Rueil-Malmaison, France 2017
- 67 inproceedingsMouse, Tactile, and Tangible Input for 3D ManipulationProceedings of the ACM Conference on Human Factors in Computing Systems (CHI)New YorkACM2017, 4727--4740
- 68 techreport Usability Comparison of Mouse, Touch and Tangible Inputs for 3D Data Manipulation https://arxiv.org/abs/1603.08735v2 Inria April 2016
- 69 inproceedingsReducing Affective Responses to Surgical Images through Color Manipulation and StylizationProceedings of the Joint Symposium on Computational Aesthetics, Sketch-Based Interfaces and Modeling, and Non-Photorealistic Animation and RenderingNew YorkACM2018, 4:1--4:13
- 70 article STATISTICAL COGNITION: TOWARDS EVIDENCE-BASE PRACTICE IN STATISTICS AND STATISTICS EDUCATION. Statistics Education Research Journal 7 2 2008
- 71 articleGeneaQuilts: A System for Exploring Large GenealogiesIEEE Transactions on Visualization and Computer Graphics166October 2010, 1073-1081
- 72 articlePerception of Visual Variables on Tiled Wall-Sized Displays for Information Visualization ApplicationsIEEE Transactions on Visualization and Computer Graphics18122012, 2516-2525
- 73 miscVisualiser un milliard (et au-delà) d'évènements en Python~: de l'idée au prototype interactifMarch 2018, URL: https://gricad.univ-grenoble-alpes.fr/video/visualisez-milliard-et-au-dela-d-evenements-en-python-l-idee-au-prototype-interactif
- 74 inproceedingsShowing people behind data: Does anthropomorphizing visualizations elicit more empathy for human rights data?Proceedings of the 2017 CHI Conference on Human Factors in Computing SystemsACM2017, 5462--5474
- 75 incollectionInteraction for Immersive AnalyticsImmersive AnalyticsBerlin /HeidelbergSpringer2018, 495--138
- 76 book S. Card J. Mackinlay B. Shneiderman Readings in information visualization: using vision to think San Francisco, CA, USA Morgan Kaufmann Publishers Inc. 1999
- 77 article Conceptual and Methodological Issues in Evaluating Multidimensional Visualizations for Decision Support IEEE Transactions on Visualization and Computer Graphics 24 2018
- 78 article The Attraction Effect in Information Visualization IEEE Transactions on Visualization and Computer Graphics 23 1 2017
- 79 phdthesis Information Visualization for Decision Making: Identifying Biases and Moving Beyond the Visual Analysis Paradigm Paris Saclay 2017
-
80
inproceedingsVisual Showcase: An Illustrative Data Graphic in an 18
–19 Century Style'Visual Showcase at the Joint ACM/EG Symposium on Computational Aesthetics, Sketch-Based Interfaces and Modeling, and Non-Photorealistic Animation and Rendering (Expressive, July 19--20, Anaheim, CA, USA)2013, URL: https://tobias.isenberg.cc/VideosAndDemos/Bach2013IDG - 81 incollectionFair statistical communication in HCIModern Statistical Methods for HCISpringer2016, 291--330
- 82 techreportHCI Statistics without p-valuesRR-8738InriaJune 2015, 32
- 83 articleBlinded with Science or Informed by Charts? A Replication StudyIEEE Transactions on Visualization and Computer Graphics241January 2018, 781-790
- 84 inproceedings Increasing the Transparency of Research Papers with Explorable Multiverse Analyses CHI 2019 - The ACM CHI Conference on Human Factors in Computing Systems Glasgow, United Kingdom May 2019
- 85 inproceedingsIllustrative Data Graphic Style ElementsPosters at the Joint ACM/EG Symposium on Computational Aesthetics, Sketch-Based Interfaces and Modeling, and Non-Photorealistic Animation and Rendering (Expressive, July 19--20, Anaheim, CA, USA)2013, URL: https://tobias.isenberg.cc/VideosAndDemos/Bach2013IDG
- 86 incollectionImmersive Analytics: An IntroductionImmersive AnalyticsBerlin /HeidelbergSpringer2018, 11--23
- 87 articleProgressive Data Analysis and Visualization (Dagstuhl Seminar 18411)Dagstuhl Reports8102018, 1--32URL: https://doi.org/10.4231/DagRep.8.1.1
- 88 unpublishedProgressive Analytics: A Computation Paradigm for Exploratory Data AnalysisJuly 2016, https://arxiv.org/abs/1607.05162 - working paper or preprint
- 89 book Data stream management: processing high-speed data streams Springer 2016
- 90 book Handbook of sequential analysis CRC Press 1991
- 91 articleRig animation with a tangible and modular input deviceACM Transactions on Graphics (TOG)3542016, 144
- 92 articleHow capacity limits of attention influence information visualization effectivenessIEEE Transactions on Visualization and Computer Graphics18122012, 2402--2410
- 93 articlePersonal Visualization and Personal Visual AnalyticsIEEE TVCG2132015, 420--433
- 94 articleThe Spatial Resolution of Visual AttentionCognitive Psychology4332001, 171---216URL: http://www.sciencedirect.com/science/article/pii/S0010028501907558
- 95 articleHybrid-image visualization for large viewing environmentsIEEE TVCG19122013, 2346--2355
- 96 articleCollaborative Visual Analytics Around a Tabletop DisplayIEEE TVCG185May 2012, 689--702
- 97 incollection Interactive Exploration of Three-Dimensional Scientific Visualizations on Large Display Surfaces Collaboration Meets Interactive Spaces Berlin, Heidelberg Springer 2016
- 98 article Data Visualization on Interactive Surfaces: A Research Agenda IEEE CG & A 33 2 mar # / 2013
- 99 articleVisualization on Interactive Surfaces: A Research Overviewi-com123November 2013, 10--17
- 100 inproceedingsPreference Between Allocentric and Egocentric 3D Manipulation in a Locally Coupled ConfigurationACM Symposium on Spatial User InteractionNew YorkACM2016, 79--88
- 101 inproceedingsA Tangible Volume for Portable 3D Interaction2016 IEEE International Symposium on Mixed and Augmented RealityLos AlamitosIEEE Computer Society2016, 215--220
- 102 articleAnalysis of Locally Coupled 3D Manipulation Mappings Based on Mobile Device MotionMIT Presence261October 2017, 66-95
- 103 articleAn Interaction Model for Visualizations Beyond The DesktopIEEE Transactions on Visualization and Computer Graphics1912November 2013, 2396 - 2405
- 104 inproceedingsEvaluating the efficiency of physical visualizationsProc. CHIACM2013, 2593--2602
- 105 inproceedingsTangible Remote Controllers for Wall-Size DisplaysACM annual conference on Human Factors in Computing Systems. CHI '12ACMAustin, TX, United StatesMay 2012, 2865-2874
- 106 inproceedings Opportunities and Challenges for Data Physicalization Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI) ACM New York, NY, United States April 2015
- 107 miscWhat Did Authors Value in the CHI'16 Reviews They Received?May 2016,
- 108 phdthesis Physical and Tangible Information Visualization Université Paris Sud-Paris XI 2014
- 109 articleA Declarative Rendering Model for Multiclass Density MapsIEEE Transactions on Visualization and Computer Graphics251January 2019, 470-480
- 110 miscSciPy: Open source scientific tools for Python[Online; accessed <today>]2001, URL: http://www.scipy.org/
- 111 book Thinking, Fast and Slow Farrar, Straus and Giroux 2011
- 112 miscSpecial Interest Group on Transparent Statistics in HCIMay 2016,
- 113 miscMoving Transparent Statistics Forward at CHIWorkshopMay 2017,
- 114 inproceedingsStackables: combining tangibles for faceted browsingProceedings of the International Working Conference on Advanced Visual InterfacesACM2012, 241--248
- 115 inproceedings Skipping the Replication Crisis in Visualization: Threats to Study Validity and How to Address Them Evaluation and Beyond - Methodological Approaches for Visualization Berlin, Germany October 2018
- 116 articleBELIV 2014 Special IssueInformation Visualization154October 2016, 286-287
- 117 articleVIS Author Profiles: Interactive Descriptions of Publication Records Combining Text and VisualizationIEEE Transactions on Visualization and Computer Graphics251January 2019, 152-161
- 118 inproceedings Zooids: Building Blocks for Swarm User Interfaces Proceedings of the 29th Annual Symposium on User Interface Software and Technology (UIST) Tokyo, Japan October 2016
- 119 article Dynamic Composite Data Physicalization Using Wheeled Micro-Robots IEEE Transactions on Visualization and Computer Graphics 2018
- 120 phdthesis Supporting Versatility in Tangible User Interfaces Using Collections of Small Actuated Objects Université Paris-Saclay December 2016
- 121 articleBeyond Mouse and Keyboard: Expanding Design Considerations for Information Visualization InteractionsIEEE TVCG1812December 2012, 2689--2698
- 122 articleTowards an Understanding of Mobile Touch Navigation in a Stereoscopic Viewing Environment for 3D Data ExplorationIEEE Transactions on Visualization and Computer Graphics225May 2016, 1616-1629
- 123 articleDimSUM: Dimension and Scale Unifying Maps for Visual Abstraction of DNA Origami StructuresComputer Graphics Forum373June 2018, 403-413
- 124 articleMultiscale Visualization and Scale-Adaptive Modification of DNA NanostructuresIEEE Transactions on Visualization and Computer Graphics241January 2018, 1014--1024
- 125 article Multiscale Molecular Visualization Journal of Molecular Biology To appear 2019
- 126 inproceedingsResponse Time in Man-computer Conversational TransactionsProc. of the Fall Joint Computer Conference, Part ISan Francisco, CaliforniaACM1968, 267--277URL: http://doi.acm.org/10.1145/1476589.1476628
- 127 articleA `dipper' function for texture discrimination based on orientation varianceJournal of Vision81108 2008, 9-9URL: https://dx.doi.org/10.1167/8.11.9
- 128 articleRegistered Reports: A method to increase the credibility of published resultsSocial Psychology453may 2014, 137--141URL: https://doi.org/10.1027/1864-9335/a000192
- 129 articleMultiscale Visualization and Exploration of Large Bipartite GraphsComputer Graphics Forum373June 2018, 12
- 130 proceedings M. Sedlmair P. Isenberg T. Isenberg N. Mahyar H. Lam Proceedings of the Sixth Workshop on ``Beyond Time and Errors: Novel Evaluation Methods for Visualization'' (BELIV 2016, October 24, Baltimore, Maryland, USA) New York ACM 2016
- 131 inproceedings Understanding the Use of The Vistorian: Complementing Logs with Context Mini-Questionnaires Visualization for the Digital Humanities Phoenix, United States October 2017
- 132 articleResponse Time and Display Rate in Human Performance with ComputersACM Comput. Surv.163September 1984, 265--285URL: http://doi.acm.org/10.1145/2514.2517
- 133 book Information Visualization Boston, MA, USA Addison-Wesley Publishing Company 2000
- 134 inproceedingsSupporting the Design and Fabrication of Physical VisualizationsProc. CHIToronto, Ontario, CanadaACM2014, 3845--3854
- 135 articlePerceiving group behavior: Sensitive ensemble coding mechanisms for biological motion of human crowds.Journal of Experimental Psychology: Human Perception and Performance3922013, 329
- 136 articleFour types of ensemble coding in data visualizationsJournal of Vision16503 2016, 11-11URL: https://dx.doi.org/10.1167/16.5.11
- 137 miscTableau SoftwareLast accessed Feb 20182018, URL: http://www.tableau.com
- 138 manualR: A Language and Environment for Statistical ComputingR Foundation for Statistical ComputingVienna, Austria2019, URL: https://www.R-project.org
- 139 articleProgressive Data Science: Potential and ChallengesCoRRabs/1812.080322018, URL: http://arxiv.org/abs/1812.08032
- 140 articleLife after NHST: How to describe your data without ``p-ing'' everywhereBasic and Applied Social Psychology3752015, 260--273
- 141 articlePondering the Concept of Abstraction in (Illustrative) VisualizationIEEE Transactions on Visualization and Computer Graphics249September 2018, 2573--2588
- 142 inproceedingsSpecial Interest Group on Transparent Statistics GuidelinesCHI 2018 - Conference on Human Factors in Computing SystemsMontreal QC, FranceACM PressApril 2018, 1-4
- 143 book Information Visualization -- Perception for Design Morgan Kaufmann Series in Interactive Technologies San Francisco, CA, USA Morgan Kaufmann Publishers 2000
- 144 articleDegrees of Freedom in Planning, Running, Analyzing, and Reporting Psychological Studies: A Checklist to Avoid p-HackingFrontiers in Psychology72016, 1832URL: https://www.frontiersin.org/article/10.3389/fpsyg.2016.01832
- 145 articleEmbedded Data RepresentationsIEEE Transactions on Visualization and Computer Graphics2017, 461 - 470
- 146 articleIllustrative Molecular Visualization with Continuous AbstractionComputer Graphics Forum303May 2011, 683--690URL: https://tobias.isenberg.cc/VideosAndDemos/Zwan2011IMV