

Section: New Software and Platforms
New Software
CliqueSquare
CliqueSquare allows storing and querying very large volumes of RDF data in a massively parralel fashion in a Hadoop cluster. The system uses its own partitioning and storage model for the RDF triples in the cluster.
CliqueSquare evaluates queries expressed in a dialect of the SPARQL query language. It is particularly efficient when processing complex queries, because it is capable of translating them into MapReduce programs guaranteed to have the minimum number of successive jobs. Given the high overhead of a MapReduce job, this advantage is considerable.
Compact
Compact reformulates conjunctive queries in the setting of ontology-based query anwering. It takes as input a conjunctive query and an ontology, and outputs a first-order rewriting of that query whenever it exists (without termination guarantee when it does not exists). To ease its use and dissemination, a novel version has been implemented by M. Thomazo based on the framework GRAAL, developed within the Inria Sophia-Antipolis team GraphIK by C. Sipieter, an engineer funded by an ADT. It will in particulary ease the integration with Semantic Web standards, as well as the use of query optimization techniques developed within Cedar for RDFS and DL-Lite to more general ontology languages.
RDF-Commons
RDF-Commons is a set of modules providing the abilities to i) load and store RDF data in a DBMS ii) parse RDF conjunctive queries iii) encode URIs and literals into integers iv) encode RDF conjunctive queries v) build statistics on RDF data vi) estimate the cost of the evaluation of a conjunctive query vii) saturate the RDF data, with respect to an RDF Schema viii)reformulate a conjunctive query with respect to an RDF Schema (ix) propose algebraic plans.
The algebraic plan part has been developed by A. Solimando and D. Bursztyn. An ADT funding for two years has been granted to consolidate and extend the development of RDF-Commons. The hiring process is ongoing.
RDFSummary
RDF Summary is a standalone Java software capable of building summaries of RDF graphs. Summaries are compact graphs (typically several orders of magnitude smaller than the original graph), which can be used to get acquainted quickly with a given graph, they can also be used to perform static query analysis, infer certain things about the answer of a query on a graph, just by considering the query and the summary.
Tatooine
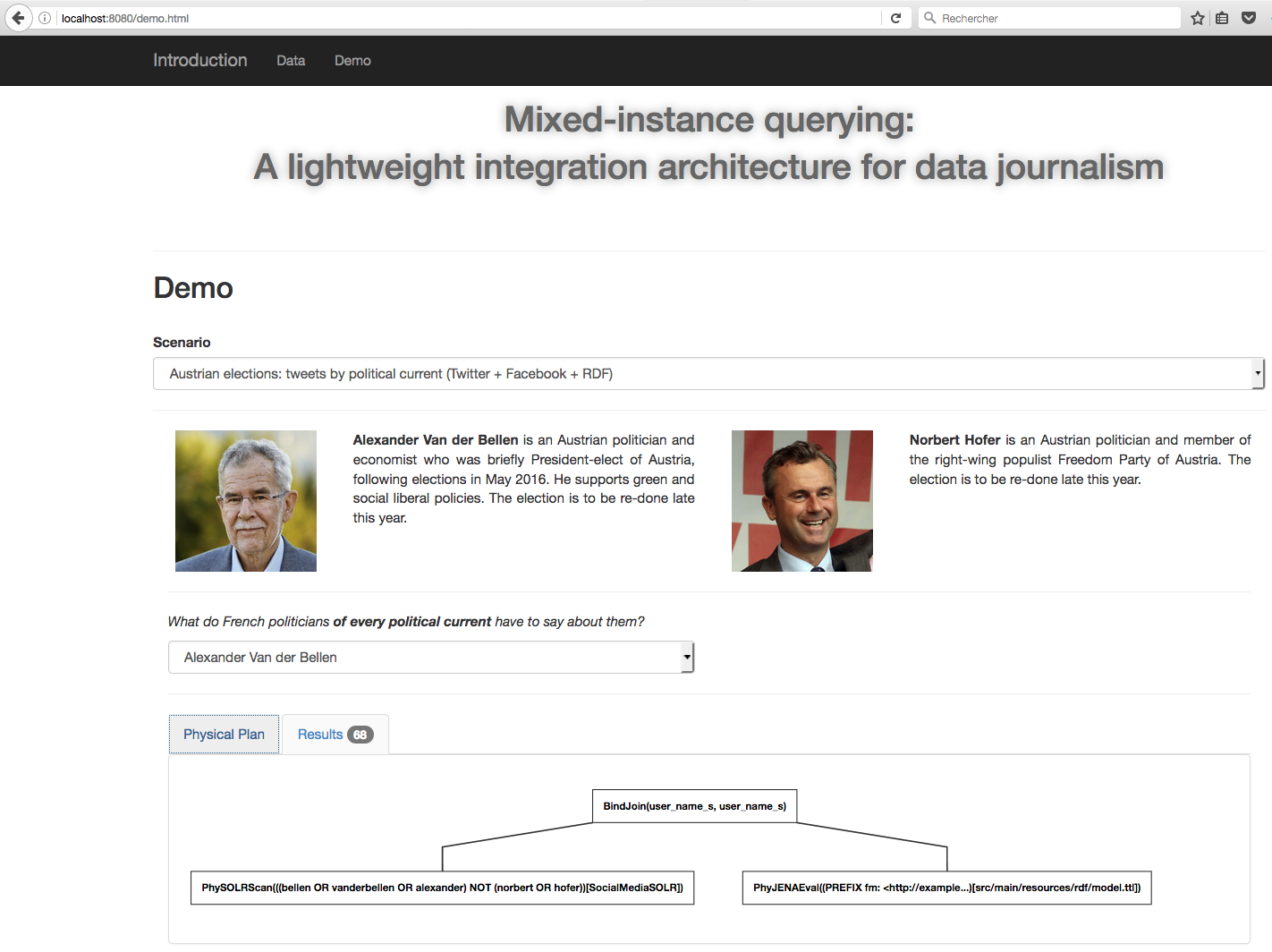
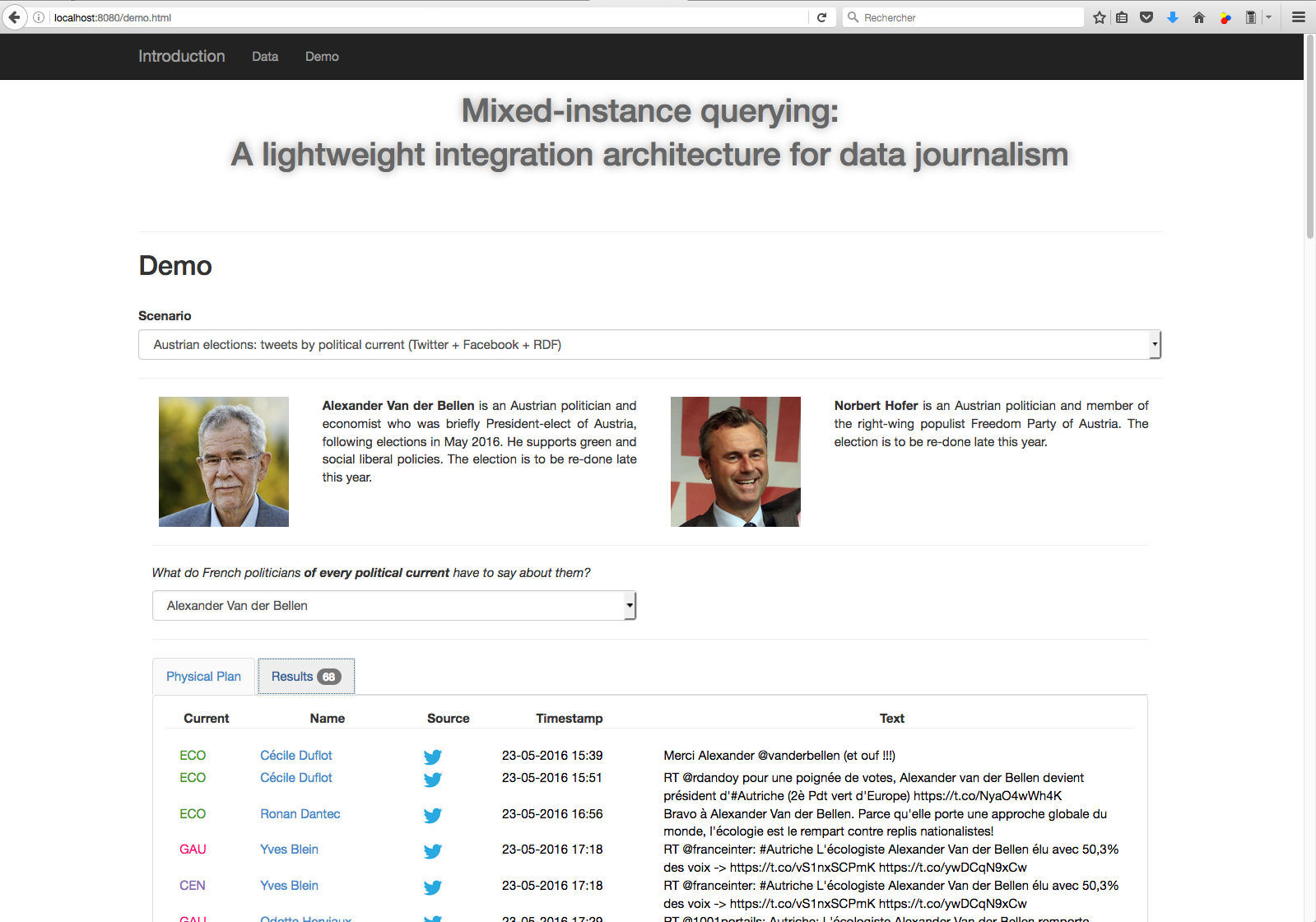
We developed lightweight data integration system called Tatooine, based on our discussions with our journalist partners in the ANR ContentCheck project from the team “Les Décodeurs”. Tatooine allows to exploit heterogeneous data sources of different data models, which we view as a mixed data instance, by querying them together; Tatooine combines data from various sources within an integrated engine complemented by information extraction and data visualization modules. Figure 1 illustrates the functioning of Tatooine through screen captures: a set of tweets (JSON documents stored in SOLR) obtained through a full-text search are combined with information about their authors (RDF metadata stored in Jena TDB) and the results are presented to the users highlighting the political affiliation of the tweet authors.